
7 Signs Your AI Codebase Is Becoming Unmaintainable
AI-built codebases can rot quietly until a small change takes a week. Here are seven early warning signs — and what to do before it's a rewrite.
An unmaintainable AI codebase rarely announces itself. It doesn't crash on a Tuesday or throw a red error in your terminal. It shows up as friction — a one-line change that eats a day, a new hire who can't ship in their first week, a bug fix that quietly breaks something three files away. By the time the symptoms are obvious, you've usually stacked eighty files on an architecture no human ever chose. Unwinding that is its own project.
Here's the answer-first version. The signs your AI codebase is becoming unmaintainable trace back to one root cause: the AI generates code faster than anyone is establishing structure for it to live in. Reliability, architecture, and the long-term cost of vibe coding are the same problem from three angles. Let a stateless model improvise your system one prompt at a time and you don't get a designed codebase. You get a sediment of forty independent decisions that happen to compile. The seven signs below are the early tells, and most of them show up months before velocity actually inverts.
This isn't an argument against AI-assisted development. The speed is real and worth keeping. It's an argument for catching the warning signs while they're still cheap to fix, and for putting a structure underneath the AI so the next thousand generations land inside a system you control instead of accreting one you don't. Catch three or more of these in your own product and you're not failing. You're at the exact point where intervention is still a refactor and not a rewrite.
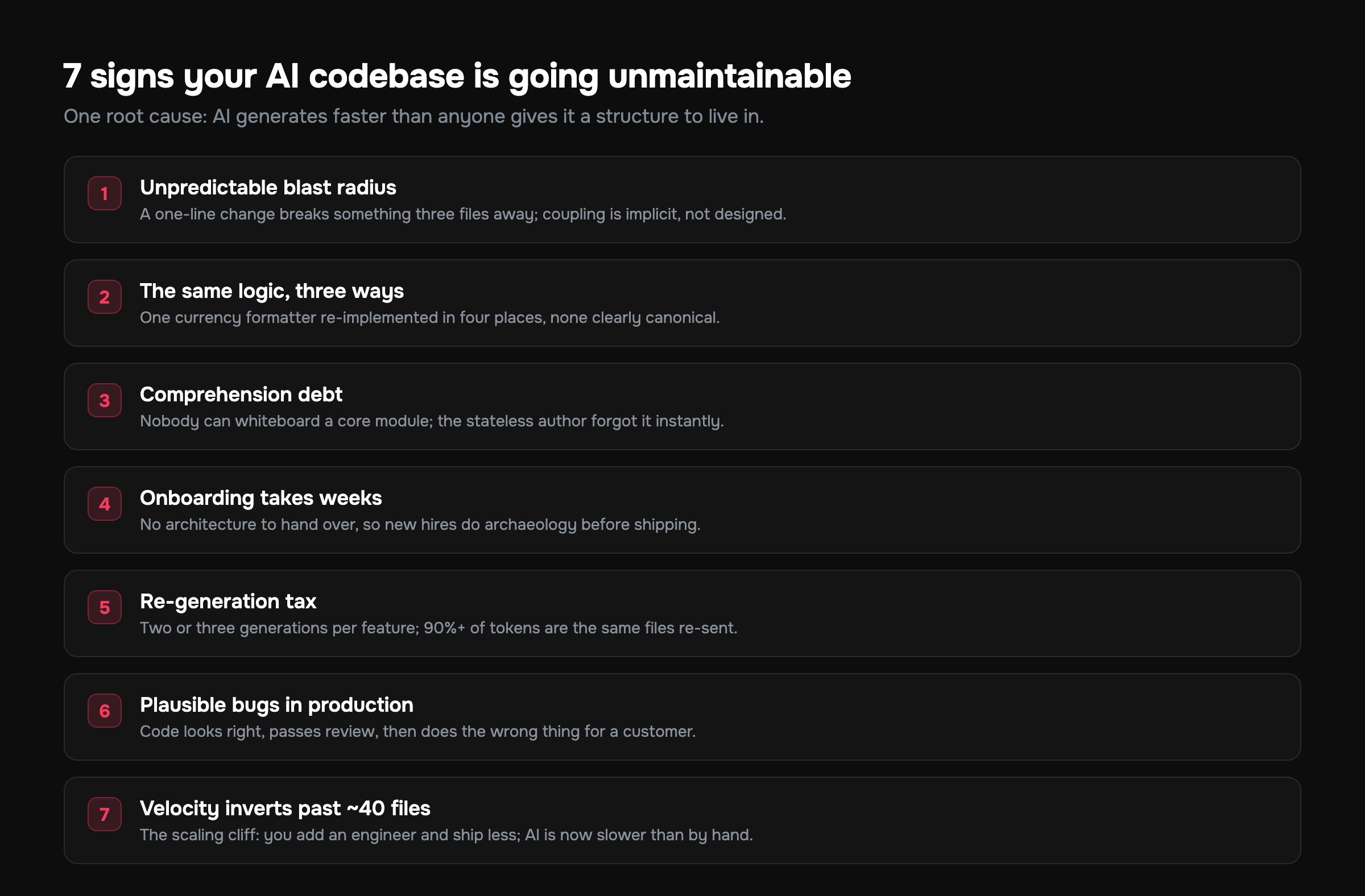
Sign 1: A one-line change has an unpredictable blast radius
The clearest sign your AI codebase is becoming unmaintainable is that you can no longer predict what a small change will break. You edit the pricing tier logic and the booking confirmation email stops sending. You rename a field and a dashboard you forgot existed goes blank. Nobody can say where the canonical version of anything lives, so every edit is a gamble you resolve at runtime.
Vibe-coded systems have implicit coupling instead of designed interfaces. The model wired two modules together through a path it invented back in prompt 14 and never recorded. No diagram, no contract, no boundary — just a dependency that exists in the code and in nobody's head.
If your team's risk assessment for a change is "let's deploy it and watch the logs," you don't have an architecture. You have a probability distribution.
A healthy codebase has a blast radius you can reason about before you act. Touch the auth module and you know it can only affect things downstream of auth, because there's an explicit boundary there. The fix isn't more caution. It's making the architecture visible and the interfaces real, so coupling becomes a decision rather than an accident. That's the entire premise of building software with AI you can see: when data flows and module boundaries are modeled objects, blast radius stops being a surprise.
Sign 2: The same logic is implemented three different ways
Open your codebase and search for how you format a currency, validate an email, or call your own API. Find three or four slightly different implementations — none of them clearly the "right" one — and that's not a style nitpick. It's the single most reliable quantitative signal that AI is eroding your maintainability.
This isn't anecdotal. Research from McKinsey on generative AI and developer productivity found that AI coding assistants speed up routine code generation substantially, but those gains erode on complex, unfamiliar tasks unless teams pair the tools with strong engineering practices like code review and refactoring discipline. So the duplication is structural. The model is rewarded for producing a plausible local solution, and with no enforced reuse it copy-pastes rather than consolidates. AI assistants are extraordinarily good at producing a plausible local solution. They have zero incentive to reuse the one that already exists two folders over.
Why this is expensive, not just ugly:
- Bugs multiply silently. Duplicated clones are a well-documented defect magnet — you fix the bug in one copy, miss the other two, and now your system behaves three different ways depending on the path.
- Every fix is N fixes. A security patch isn't one change, it's a manhunt for every place the model re-implemented the same logic.
- The codebase has no canonical truth. New code can't reuse what already works because nobody knows which version is blessed.
The structural fix is reuse the system enforces, not reuse you hope for. When generation happens against a library of reusable components — a validated currency formatter, one auth guard, one API client — the model fills in parameters instead of re-deriving the wheel. That's also where the token savings come from: generating against existing components instead of regenerating logic from scratch is a large part of how you get to roughly 15x fewer tokens per feature.
Sign 3: Nobody on the team can explain how a module works
Ask any engineer on your team to whiteboard how a core module works — say, how a booking flows from request to confirmation. If the honest answer is "let me open the code and figure it out," you have comprehension debt. It's the most underpriced liability in AI-built software.
Technical debt is code you know is bad. Comprehension debt is code nobody understands at all, good or bad. In a hand-written system, the author of a module carries a mental model, and that model is recoverable from the structure they deliberately chose. In a vibe-coded one, the "author" is a stateless model that produced the code and forgot it in the same breath. There was never a mental model to recover. The structure is an artifact of forty prompts, not a single decision.
The most expensive sentence in any codebase is "I'm not sure why it does that, but don't touch it." Every instance is a region that has become economically frozen — too risky to change, too important to delete.
This sign compounds quietly. It shows up first as reviews becoming theater — checking that AI output looks plausible, which is exactly the thing the model guarantees and exactly the wrong thing to verify. We go deep on the rest of this in the hidden cost of vibe coding, but the short version is that comprehension debt never appears on a dashboard. You pay it in engineer-hours spent re-deriving a system that was never designed, and it gets worse every week you ignore it.
Sign 4: Onboarding a new engineer takes weeks, not days
A new engineer is a maintainability stress test you can't fake. If ramping them takes three weeks instead of three days, the codebase is failing the test, and the reason is almost always the same: there's nothing to point at.
Onboarding works when a new person can build a mental model from artifacts — an architecture diagram, named modules, clear data flows, conventions they can read. A vibe-coded product has none of these. The "documentation" is a scrollback in someone's editor and a Loom the founder recorded six weeks ago. The tribal knowledge lives in two people's heads and in chat histories nobody will ever read again.
Here's the realistic scenario. A two-founder B2B SaaS hires their first engineer at month six, ninety files in. There's no architecture to hand over, just a repo and a verbal tour. The new hire spends two weeks doing archaeology before writing a line, then ships their first change and breaks something nobody warned them about, because the coupling was invisible. The founders conclude "this person is slow." The person is fine. The codebase is unteachable.
The cure isn't writing docs after the fact — stale docs are worse than none. It's structure that is the documentation, generated and kept current as you build. We covered the playbook in onboarding engineers faster and the automated version in documenting software architecture automatically. When the architecture is a live, visual model of the system, onboarding becomes "here's the map" instead of "good luck."
Sign 5: You re-generate the same feature two or three times
Watch your own prompting loop. If you routinely ask the AI to build something, then re-ask because the output drifted from the rest of the system, then re-ask again to fix what the second version broke, that re-generation tax is a maintainability signal, not just a cost signal.
A model drifts because it has no durable view of your system. Each generation is a fresh improvisation against an architecture it can't fully see. It produces something plausible, you discover it doesn't fit, and you pay — in tokens and in attention — to redo work you already did. A typical ad-hoc loop on a mid-size codebase looks like this:
| Turn | What happened | What it cost |
|---|---|---|
| Initial ask | Whole-file context attached | Big input, small useful output |
| "Fix the type error" | Re-sends the same files + error | Same input again |
| "Wire it to the API" | Pulls in more files it should have known about | More input |
| "It broke the tests" | Test output + files, round four | More input |
Most of those tokens are the same files re-sent because the model has no persistent model of your system — often 90%+ of spend is repeated input. But the bill isn't the real problem. A system that needs three generations to land one feature is a system the AI doesn't understand. The structural answer is to make the AI generate inside a defined architecture, so a feature has one correct shape to fill rather than an open field to improvise across. That's the difference between validating AI-generated code against a real structure and re-rolling the dice until something looks right.
Sign 6: Bugs are correct-looking and you find them in production
The most insidious sign is that your bugs aren't broken. They're plausible. The code compiles, passes a glance, ships, and then does the wrong thing in a way nobody catches until a customer does. This is the specific failure mode of AI-generated code, and it's qualitatively different from a typo or a null pointer.
A model's core competency is generating output that looks right. That's not a side effect; it's the objective it was trained on. So its errors are precisely the ones that pass a casual review — a subtly wrong timezone assumption, an off-by-one in a discount calculation, an auth check that's almost but not quite scoped correctly. These are the hallucination-class bugs we break down in shipping AI code without hallucinations.
The reliability cost stacks up like this:
- Plausible-but-wrong output passes review because review of code you didn't design is mostly a plausibility check.
- The bug ships because nothing in the pipeline validated behavior against intent.
- It surfaces in production as a support ticket, a refund, or a silent data-quality problem.
- The fix is risky because of Sign 1 — you can't predict the blast radius — so you patch narrowly and hope.
Correct-looking is the most dangerous property code can have, because it's the one thing that defeats every cheap check you have. The only defense is validation against a structure that knows what the code is supposed to do.
This is the case for validation before deploy, not bug-hunting after. When generation happens inside a modeled system — defined data flows, typed interfaces, known business rules — the system can reject output that violates the architecture before it ever reaches a user. The model still writes fast. It just can't ship something that contradicts the structure you defined.
Sign 7: Your velocity is going down, not up
The last sign is the one that finally gets a founder's attention, because it shows up on the roadmap. Features that took two days in month one take a week in month six. You added an engineer and somehow shipped less. The AI that made you feel 10x now feels like a liability you're babysitting.
This is the scaling cliff, and the defining feature is that it's non-linear. Productivity against codebase size doesn't decay gracefully. It inverts:
- 0–10 files: AI is pure leverage, 5–10x faster. The whole system fits in a context window and in your head. No structure needed, and that's the trap, because the early speed is evidence for the wrong conclusion.
- 10–40 files: Still fast, but repair loops appear. The model breaks things it can't see. You start re-explaining the system every session.
- 40–100 files: The cliff. Context no longer fits, the model over-fetches and still misses the relevant file, conventions have diverged, and a "small" change risks three things. Velocity inverts — you're now slower than building by hand.
- 100+ files: Without intervention, the codebase becomes change-resistant. Teams start rewriting modules just to make them comprehensible.
The cruel part is that the cliff is invisible from the bottom. On day one, vibe coding feels like it scales linearly forever. Research backs the pattern up: even controlled studies have found that AI tooling can slow experienced developers down on complex, mature codebases while making them feel faster — the perception of speed and the reality of it diverge exactly where the stakes are highest. We unpack the full economics of this in scaling a vibe-coded prototype to production.
How to read the signs: a quick self-assessment
You don't need all seven to be in trouble. Here's how to score yourself honestly.
| Sign | Cheap to fix (early) | Expensive to fix (late) |
|---|---|---|
| Unpredictable blast radius | Occasional surprise breakage | "Don't touch that file" zones |
| Duplicated logic | Two copies of one helper | Same logic in five places, all subtly different |
| Comprehension debt | One module nobody loves | No one can explain the core flow |
| Slow onboarding | Hire needs a week | Hire needs a month, breaks things anyway |
| Re-generation tax | Occasional re-roll | Every feature is three generations |
| Plausible bugs | Caught in staging | Found by customers in prod |
| Inverting velocity | A few slow features | Roadmap is mostly maintenance |
One or two signs, mostly in the left column: you're fine. Note them and keep building. Three or more, drifting right: you're at the intervention point — still a refactor, not a rewrite. Five or more in the right column: the structure problem is now your primary product risk, and shipping speed is a lagging indicator of a decision you made months ago.
The thing to internalize: none of these signs are about the AI being bad. The output is genuinely good. Every sign is about the absence of a structure to hold the AI accountable as the system grows past what fits in a context window.
What actually fixes it: structure first, AI inside it
The fix for all seven signs is the same, which is the good news. You don't stop using AI and you don't slow down. You change where the AI operates — from improvising against an invisible system to generating inside a visible, controlled one.
Concretely, that means:
- Model the product before generating. Define the modules, data flows, APIs, and business logic as explicit objects. The architecture becomes a decision a human made, not an accident the model produced.
- Generate inside the architecture. AI produces structured, editable objects that live in your model, not free-floating files. New code has a correct shape to fill instead of an open field to improvise across.
- Validate before deploy. Output that violates the structure — a broken data flow, a contract mismatch, a business-rule violation — gets caught before it ships, not by a customer.
- Reuse enforced components. One currency formatter, one auth guard, one API client. The model parameterizes them instead of re-implementing them, which kills the duplication in Sign 2 and a large chunk of the token cost in Sign 5.
This is the bet GitMir is built on: keep the speed of vibe coding, put a visual architecture underneath it, and let AI generate inside a system you can see and control. It's also the honest dividing line in the tooling landscape. Cursor and Copilot make a developer who owns the architecture faster — they don't provide one. Lovable and v0 get you from zero to a working app brilliantly, but the structure is theirs, and editing past the first generation is where the re-generation tax lives. Replit Agent's autonomy is a feature early and a control problem at scale. Bubble gives you real structure but trades entropy for a closed runtime and lock-in. None of them are villains. They're each strong at a different point on the curve. The side-by-side comparison lays out where each one's design point ends.
The goal isn't to write less code with AI. It's to make sure the thousandth thing the AI generates is as maintainable as the first — because that's the one that's actually running your business.
Recognize three or more of these signs and the next move isn't a rewrite, and it isn't quitting AI. It's putting structure in place before the curve bends further. The fastest way to see what that looks like is the product itself — a visual architecture with AI generating inside it. And if you want the number that makes the case to your team, the ROI calculator turns the re-generation tax, the comprehension debt, and the inverting velocity into a dollar figure you can actually act on. And starting is free — cheaper than the maintenance curve you're already paying for in silence.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
What are the signs that an AI-generated codebase is becoming unmaintainable?
The clearest signs are unpredictable blast radius on small changes, the same logic implemented multiple ways, comprehension debt where nobody can explain core modules, onboarding that takes weeks, repeated re-generation of features, plausible-but-wrong bugs found in production, and velocity that inverts as the codebase grows past roughly 40 files.
Why does AI-generated code create so much duplicated code?
AI models optimize for a plausible local solution and have no incentive to reuse existing logic, so they re-implement helpers that already exist. Studies of AI-assisted codebases have found duplicated code blocks rising sharply while refactoring falls below 10% of changes. The fix is enforced reusable components the model parameterizes instead of regenerating.
Is vibe coding bad for production software?
Vibe coding isn't bad — it's mismatched. It's designed for disposable, low-stakes projects, and the front-loaded speed is real. The problem is carrying a disposable-code methodology into software with real users, where the deferred costs (comprehension debt, duplication, inverting velocity) come due. Production needs structure underneath the AI, not less AI.
How can I make AI-generated code more reliable and maintainable?
Model your architecture before generating, have the AI produce structured objects inside that architecture rather than free-floating files, validate output against the structure before deploy, and enforce reusable components. This catches plausible-but-wrong bugs early, kills duplication, and keeps blast radius predictable as the system grows beyond a context window.
At what point does an AI codebase hit the scaling cliff?
Most AI-built codebases hit the cliff between roughly 40 and 100 files. Below 10 files AI is pure leverage; from 10 to 40 repair loops appear; past 40 the context no longer fits, conventions diverge, and velocity inverts so you're slower than building by hand. The cliff is invisible from the bottom, which is why early signs matter.
Can I fix an unmaintainable AI codebase without a full rewrite?
Usually yes, if you catch it early. With three or four warning signs it's still a refactor: extract reusable components, model the existing architecture explicitly, and route future generation through that structure. A full rewrite only becomes necessary once five or more signs are deep in the expensive column and the codebase is already change-resistant.

Related articles

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.

AI Coding Without Hallucinations: Keep AI From Breaking Your Architecture
AI doesn't 'hallucinate' randomly — it invents code when it can't see the system. Give it structure and validation, and the hallucinations stop being your problem.

What Is AI-Native Development? A Plain-English Guide
AI-native development means building software where AI is the primary builder and humans direct, review and architect. Here's what changes, what stays, and how to do it without losing control.