
Lovable vs GitMir: AI App Builder vs AI-Native System
Lovable generates apps from prompts, fast. GitMir gives you a visual, controllable system for complex products. Here's how they differ and which fits your project.
If you're comparing Lovable vs GitMir, here's the short version before the long one. Lovable is an AI app builder that turns a chat prompt into a running full-stack web app, astonishingly fast. GitMir is an AI-native system — you model the product as visual architecture (modules, data flows, APIs, business logic) and AI generates structured, validated objects inside that architecture. Lovable optimizes for "how do I get something live today." GitMir optimizes for "how does this thing stay coherent at version forty." They overlap at the demo and diverge hard at the product.
That difference isn't cosmetic, and it isn't about which tool is "better." It's about where each one puts the source of truth. In Lovable, the truth is the conversation plus whatever code the last prompt happened to emit. In GitMir, the truth is an architecture you can see and constrain, and the AI is a generator working within those constraints rather than re-inventing the world each message. That one design decision changes how the output ages, how much you re-explain to the model, and whether a non-founder can ever safely touch the codebase.
So if you're a founder choosing between an AI app builder and an AI-native system, the real question isn't "which produces a nicer first screen?" Both are good at that now. The question is which one you're still happy with after three months of changes, a second engineer, and a paying customer who found a bug at 2am. This piece walks through where Lovable shines, where its model of the world ends, and where an architecture-first platform like GitMir picks up — including the cases where reaching for GitMir is overkill and you should just stay in Lovable.
What Lovable actually is (and why people love it)
Lovable is a prompt-to-app builder. You describe the product you want in natural language, and it scaffolds a working full-stack web application — UI, components, routing, often a backend and database wired in — that you can preview live and keep refining by chatting. It sits in the same broad category as Replit Agent, v0, and Bolt: tools that compress "idea" to "deployed thing" into an afternoon. Calling it no-code isn't quite right. It's low-code, because you can drop into the code, but most users live almost entirely in the chat.
What it's genuinely excellent at:
- Zero-to-running in minutes. "Build a CRM for a small plumbing business with quotes, jobs, and invoices" comes back as something you can click through. That used to be a week of scaffolding.
- Full-stack, not just UI. Unlike a pure generative-UI tool, Lovable will stand up auth, a database, and CRUD without you stitching services together by hand.
- Conversational iteration. "Make jobs filterable by status, and email the customer when a quote is accepted" feels like delegating to a fast junior full-stack dev.
- Genuinely accessible. A non-engineer founder can get to a clickable, shareable MVP without ever opening a terminal. That's not a small thing — it collapses the cost of validating an idea.
Lovable's superpower is collapsing the distance between "I have an idea" and "I have a thing strangers can use." For prototypes, internal tools, and the first version of a startup, that's an unfair advantage.
If your job this week is to get a believable MVP in front of ten users and learn something, Lovable is close to the right tool, full stop. Most of what follows isn't a knock on Lovable doing that job. It's about what happens when the job quietly changes from "build an app" to "run a product."
The layer an app builder doesn't model: your system
Here's what the chat interface gently hides. An AI app builder reasons about the app it is generating right now, conditioned on your prompt and the current code. It has a strong model of features and a weak-to-implicit model of the system those features belong to. That's not a flaw in Lovable specifically — it's the nature of prompt-to-app generation. But it shapes everything about how the output behaves over time.
A real application isn't a stack of features. It's:
- Modules with clear responsibilities and boundaries.
- Data flows — where state originates, who owns it, how it moves between client and server.
- APIs — the contracts between front end, back end, and third parties.
- Business logic — the rules that make the product the product, usually referenced from many places.
- Persistence — schemas, migrations, the things that outlive any single feature.
An app builder will happily produce all of these. Ask for invoicing and it scaffolds a table, an endpoint, some types. But it's generating a plausible local instance of each concept, prompt by prompt, with no enforced global model holding them together. Generate the "customer" entity in the quotes feature, then again in the invoicing feature, and you can easily end up with two subtly different shapes, two fetch patterns, two places the validation lives.
The failure mode isn't ugly code. It's incoherent code: every individual feature looks right, and the whole refuses to add up. That incoherence is invisible at feature #3 and load-bearing at feature #30.
This is the exact gap an architecture-first platform exists to close, and it's the same structural argument behind building software with AI you can actually see: if the system isn't a thing you can look at and constrain, the AI has nothing to stay consistent with. It just has the last message and a best guess.
How GitMir is different: AI inside a controlled architecture
GitMir inverts the order of operations. Instead of "prompt → app, then hope it's coherent," you build the architecture first — visually — and then let AI generate inside it.
Concretely, that means:
- You model the product as visual architecture. Modules, data flows, APIs, and business logic become objects you can see, name, and connect. The system stops being implied by scattered code and becomes a thing on screen you can point at.
- **AI generates into that architecture.** When you ask for a feature, the model isn't free-associating a fresh app. It's producing structured, editable objects that slot into modules and contracts you already defined. The architecture is the constraint, so output stays consistent with it by construction.
- Components are reusable, not re-generated. A business rule like "a quote expires 30 days after it's sent unless accepted" is one component referenced everywhere it applies — the customer view, the reminder job, the admin override — instead of three near-identical reimplementations drifting apart.
- Validation happens before deploy. Because the architecture is explicit, GitMir can check the relationships between parts — does this API actually return what that module expects, does this flow respect that permission — and surface mismatches before they reach production rather than after.
The token economics fall out of this directly. When the system is an explicit, structured model, the AI doesn't need you to re-narrate the whole app on every request — the architecture carries the context. In practice that's up to roughly 15x fewer LLM tokens than ad-hoc prompting, where each change re-establishes context from scratch. We break down where that saving comes from in reducing AI token costs, and you can put your own numbers against it on the ROI calculator.
The mental model: an AI app builder asks the LLM to remember your system from a transcript. An AI-native system gives the LLM your system as a structured object it generates against. One re-derives context; the other references it.
Lovable vs GitMir: the head-to-head
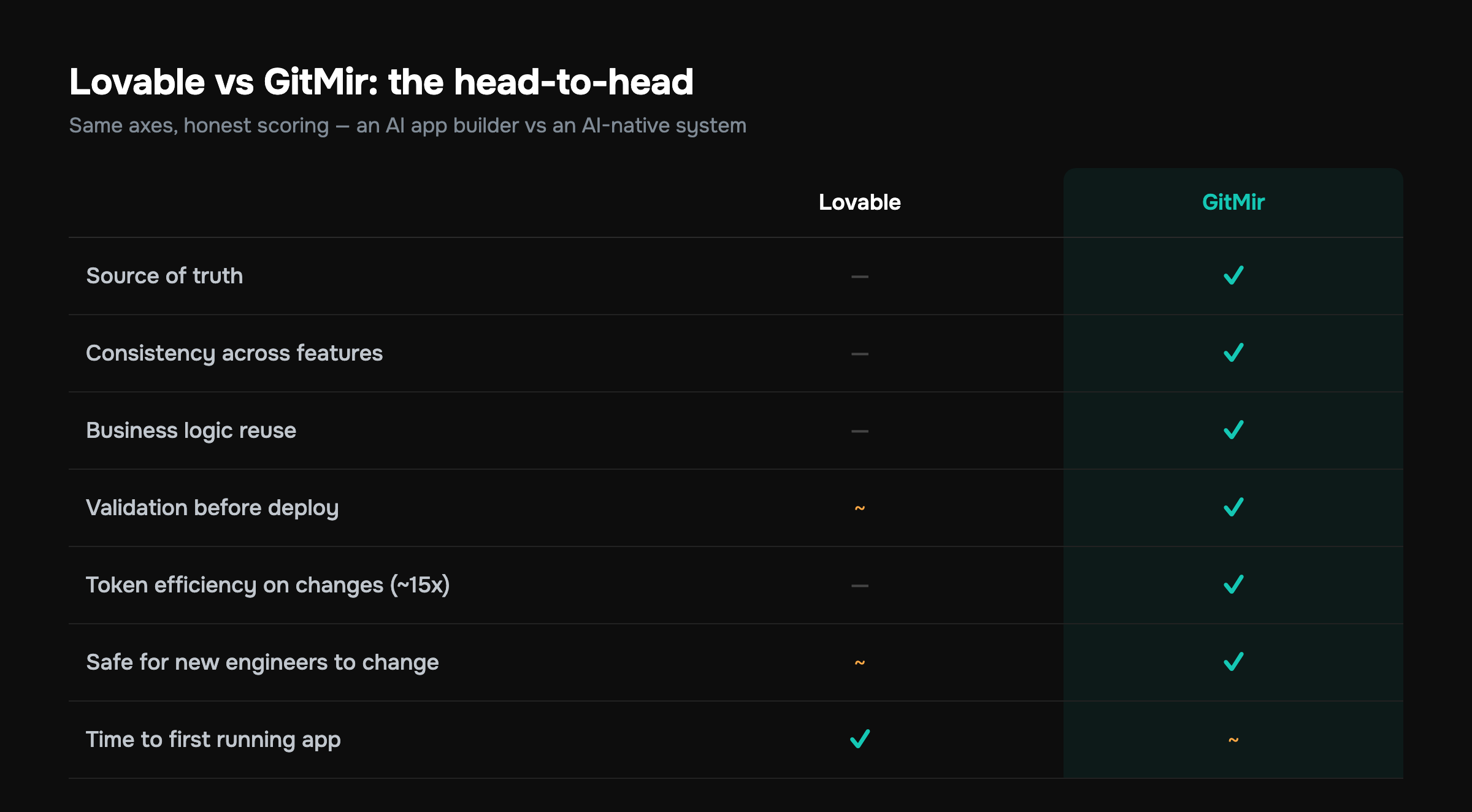
Here's the structured breakdown. Same axes, honest scoring.
| Dimension | Lovable (AI app builder) | GitMir (AI-native system) |
|---|---|---|
| Time to first running app | Minutes — best in class | Fast, but you model architecture first |
| Source of truth | Chat transcript + current code | Visible, constrained architecture |
| Consistency across features | Re-derived per prompt; drifts | Enforced by the shared model |
| Business logic reuse | Tends to duplicate per feature | One component, referenced many times |
| Validation before deploy | Runs-or-doesn't (per app) | Cross-part correctness checks |
| Token efficiency on changes | Re-explains context each prompt | Up to ~15x fewer tokens |
| Who can safely change it later | Original prompter, mostly | New engineers, via the architecture |
| Best fit | MVPs, prototypes, internal tools | Products meant to grow and be owned |
Read the table the right way. Lovable winning "time to first running app" is real, and it matters. GitMir winning "consistency at scale" is also real, and it matters later. You're not picking a better tool. You're picking which problem you want to be easy. For a deeper version of this comparison logic across the whole category, the best AI tools for startups maps tool to stage.
Where AI-built apps quietly fall apart
This is the part the demos never show, and it's where the evidence gets uncomfortable. The risk of any prompt-driven generator — Lovable, Cursor, Copilot, Replit Agent, the whole class — isn't that it writes bad code in the moment. It's that it writes locally plausible, globally incoherent code, and that incoherence accumulates.
Research from McKinsey on generative AI and developer productivity found that AI assistants deliver their biggest speedups on greenfield, low-complexity work and that those gains shrink — or reverse — as systems grow more complex and demand consistency across many parts, with maintainability and review overhead becoming the dominant cost. That's the statistical fingerprint of the exact failure mode above. AI makes it cheaper to add a near-duplicate than to reuse the right abstraction, the easy local win quietly creates a global maintenance bill, and nothing in a prompt-to-app loop pushes back.
When duplication goes up and refactoring goes down, you're not building a product — you're accumulating a cleanup bill with interest. The question is whether your tool fights that trend or feeds it.
An app builder feeds it: every feature is a fresh generation, so duplication is the path of least resistance. An architecture-first system fights it, because reuse is the default when components are first-class objects rather than text the model happens to repeat. This is the whole thesis behind signs your AI codebase is becoming unmaintainable — the symptoms are predictable, and they start early.
The 2am bug scenario
Make it concrete. You launched a Lovable app. A customer reports that accepting a quote sometimes doesn't generate an invoice. You open the chat to fix it and hit three walls:
- The "accept quote" logic exists in two places — the customer-facing action and an admin override — and they've diverged. Which one's the bug?
- Fixing one risks the other, because nothing tells you they were ever supposed to be the same rule.
- The model's context window doesn't hold your whole app, so you re-explain the data flow to get a useful answer, burning tokens and time.
In an architecture-first model, "accept quote" is one component with one defined effect. There's one place to look, the validation layer flagged the contract mismatch before deploy, and the architecture — not your memory — is what the AI reasons against. Same bug, a fraction of the blast radius.
Migration and lock-in: who owns the result
A question founders ask too late: what do I actually own, and how hard is it to leave?
Lovable generates real code and gives you access to it, which is meaningfully better than a fully proprietary no-code runtime like Bubble — there's no opaque engine you're a tenant of. But "you have the code" and "you have a maintainable system" aren't the same claim. If what you've accumulated is feature-by-feature generation with the duplication profile above, then owning it means owning the cleanup. The export is clean. The architecture is implicit, scattered across files, and lives mostly in the head of whoever did the prompting. Compare that with the proprietary lock-in trap covered in Bubble vs GitMir — Lovable avoids the worst version of it, but inherits a subtler one: code you own but can't easily reason about.
GitMir's answer is that the architecture is the artifact. Because the system is modeled explicitly, what you own isn't just files — it's a structured, visible model of how the product works, which is the thing a second engineer actually needs to onboard. That's the difference between handing someone a codebase and handing them a codebase plus the map, a point we make in onboarding engineers faster.
When Lovable is the right call (and GitMir is overkill)
Honesty matters more than positioning, so here's where I'd tell you to skip GitMir:
- You're testing whether anyone wants this at all. If you might throw it away next week, architecture is premature. Use Lovable, Replit Agent, or v0, ship the prototype, learn.
- It's a genuinely small, stable internal tool. A form-and-table app for ten coworkers that won't grow much doesn't need an architecture you'll never stress.
- You have no engineer and no plan to hire one. If the product will stay screen-and-workflow shaped and nobody will ever extend it in code, a builder's abstraction is a feature, not a debt.
- **Speed of the first version is the only thing that matters this week.** Sometimes it genuinely is. Optimize for the demo, then revisit.
The line to watch for is the transition. The moment "this prototype worked, now make it the real product" enters the conversation, you've left the zone where an app builder's trade-offs are free. That's the scale-up cliff we cover in scaling a vibe-coded prototype to production — and it's exactly where the architecture you skipped starts charging interest.
The deciding question: speed today vs coherence later
Strip away the tooling and the choice is a single bet. Are you optimizing for the speed of the next change, or the coherence of the hundredth?
For an AI app builder, every change is cheap and independent — which is great until independence becomes incoherence. For an AI-native system, every change is constrained by the architecture, which costs a little structure up front and pays it back every time the product survives contact with a real user, a second engineer, or a 2am bug.
Most founders don't choose deliberately. They reach for whatever ships the demo, then discover six months later that "the demo tool" silently became "the production system" without anyone deciding it should. The good news is you don't have to pick once and forever. Prototype in Lovable. The day it stops being a prototype, that's your signal to ask whether the architecture should become a thing you can see — not a thing you hope is consistent. If you want the side-by-side across the category, the comparison page lays out where each tool sits, and the product page shows what architecture-first generation actually looks like in motion.
The bottom line
Lovable and GitMir aren't really competing for the same moment. Lovable is the best kind of front door — it gets you from idea to running app faster than almost anything. GitMir is for the house behind the door: the system that has to stay coherent as features pile up, engineers join, and customers depend on it. One generates an app from a prompt. The other generates structured, validated objects inside an architecture you control, with reusable components and a fraction of the tokens.
The next step is concrete, not a leap. Put your own project into the ROI calculator to see what coherence, token efficiency, and avoided rework are actually worth, then watch how the architecture-first workflow runs on the product page. When you're ready, the GitMir IDE is free to start. The best time to decide who owns your architecture is before the duplication compounds — which, if you're early, is right now.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
What is the difference between Lovable and GitMir?
Lovable is an AI app builder that turns a chat prompt into a running full-stack web app fast, with the source of truth being the conversation and the code it emits. GitMir is an AI-native system where you model architecture visually first, then AI generates structured, validated objects inside it — trading a little upfront structure for long-term coherence and ownership.
Is Lovable a no-code or low-code tool?
Lovable is best described as low-code, not pure no-code. It generates real, accessible full-stack code you can drop into, but most users build and iterate entirely through natural-language chat without touching it. That's different from a proprietary no-code runtime like Bubble, where you never reach code and never leave the vendor's engine.
Can GitMir replace Lovable for building an MVP?
Yes, but it's often not the right first move. If you're validating whether anyone wants the product at all, Lovable's prompt-to-app speed is hard to beat and architecture is premature. GitMir earns its keep the moment that MVP becomes a real product that has to grow, onboard engineers, and stay coherent under change.
Why do AI-built apps get hard to maintain over time?
Because prompt-driven generators produce locally plausible but globally inconsistent code, and that incoherence compounds. Studies of AI-assisted codebases have found that duplication rises sharply while refactoring falls as AI tools spread. Each feature becomes a fresh generation, so duplicating logic is the path of least resistance unless your tool enforces reuse.
How does GitMir use fewer AI tokens than Lovable?
Because the architecture carries the context. In a chat-based app builder, every change re-narrates the system to the model, re-establishing context from scratch and burning tokens. GitMir gives the AI an explicit, structured model to generate against, so it references context instead of re-deriving it — in practice up to roughly 15x fewer tokens on changes.
When should I choose Lovable over GitMir?
Choose Lovable when speed of the first version is the only thing that matters this week — throwaway prototypes, idea validation, or small stable internal tools that won't grow. In those cases an architecture-first approach is overkill. The signal to switch is the sentence "this prototype worked, now make it the real product," where coherence starts mattering more than raw speed.

Related articles

Cursor vs Copilot vs GitMir: Which AI Coding Tool Keeps You in Control?
Cursor and Copilot make you faster at writing code. GitMir makes your whole system visible and controllable. Here's how they compare — and when you need more than autocomplete.

Cursor Alternatives: 6 Options for Teams Who Need Control
Cursor is a great AI editor, but it's not the only — or always the right — choice. Here are six alternatives, what each is best at, and when you need more than an editor.

GitHub Copilot Alternatives: Beyond Autocomplete
Copilot is excellent autocomplete — but autocomplete has a ceiling. Here are the alternatives for teams who need multi-file edits, agents, or full architectural control.