
How to Cut AI/LLM Token Costs in Development (Up to 15×)
AI coding bills scale with tokens, and ad-hoc prompting burns them fast. Here's why token spend explodes — and the pipeline changes that cut it dramatically.
If your AI coding bill is climbing and you want to reduce LLM token costs in development, the fastest lever is almost never the model you pick or the per-token price you negotiate. It's the amount of context you re-send on every turn. Most of the tokens in an AI-assisted workflow are input tokens — files, history, and conventions shoved back into the prompt over and over because the model has no durable memory of your system. Cut that re-sending and you cut the bill, often by an order of magnitude.
Here's the answer-first version. You reduce AI/LLM token costs by stopping the model from re-deriving your architecture on every prompt. Three moves do most of the work: cache the stable context so you pay for it once, retrieve only the slice of code a task actually touches instead of dumping whole files, and reuse validated components so the model regenerates nothing it has already produced correctly. Stack those, and the same feature that cost 157,000 input tokens the ad-hoc way costs closer to 10,000. That's the ~15x figure you'll see throughout this piece, and it is mechanical, not magic.
Most teams never capture this because they treat token cost as a pricing problem when it's an architecture problem. Switch from a frontier model to a cheaper one and you shave 40%. Change how context flows and you shave 90% — while getting more correct output, because a model that sees a tight, relevant context hallucinates less than one drowning in 30k tokens of mostly-irrelevant files. This article is about the second path: where the tokens actually go, the specific techniques that recover them, and how an architecture-first system makes the savings automatic instead of something you re-earn every sprint.
Where AI token costs actually come from
Before you can reduce LLM token costs, you have to know which tokens you're paying for. Almost everyone guesses wrong. They picture the model writing a lot of code and assume output is the expensive part. It's the opposite.
In a typical agentic coding session, input tokens dominate output tokens by 20x to 50x. You ask for a feature, and to answer, the model receives your prompt, several whole source files for "context," your conventions, the prior conversation, error messages from the last attempt, and often a chunk of unrelated code that the retrieval step swept in by accident. It emits a few hundred lines back. You paid for tens of thousands of tokens to receive a couple thousand.
The deeper problem is repetition. The model is stateless between calls, so every turn re-establishes the world from scratch:
- Turn 1: here are 6 files, here's what I want.
- Turn 2: here are the same 6 files again, plus a type error, please fix.
- Turn 3: same 6 files, now wire it to the API.
- Turn 4: same 6 files, the tests broke, here's the output.
By turn four you've sent the same files four times. That's the engine of cost — not the writing, the re-reading. And it scales with your codebase: the bigger the system, the more context the agent over-fetches "to be safe," and the more you pay to re-send code that has nothing to do with the task.
The expensive token isn't the one the model writes. It's the one you send it for the fourth time because nothing remembered the first three.
We broke down the dollar mechanics of this loop in detail in the hidden cost of vibe coding — the short version is that the re-generation tax and repair loops, not the base generation, are where the budget evaporates.
The repair loop is a token multiplier
There's a second, sneakier cost driver: code that doesn't work the first time. When the model produces output that fails to compile, breaks a test, or violates a convention, you feed the failure back in. That round trip is full context again plus the error plus a fresh generation.
A single repair round can cost as much as the original request. Two or three rounds — common on any non-trivial feature when the model is working blind — and you've tripled the token cost of that feature without writing a single additional line of shipped code.
Which is why correctness is a cost-control strategy, not just a quality one. Every percentage point you shave off the first-attempt failure rate removes an entire round trip of full-context input tokens. Tools that validate output against a real structure before you ever see it — instead of letting you discover the breakage by running it — collapse the repair loop at its source. That's the connection between validating AI-generated code and your monthly bill: fewer invalid generations means fewer expensive re-prompts.
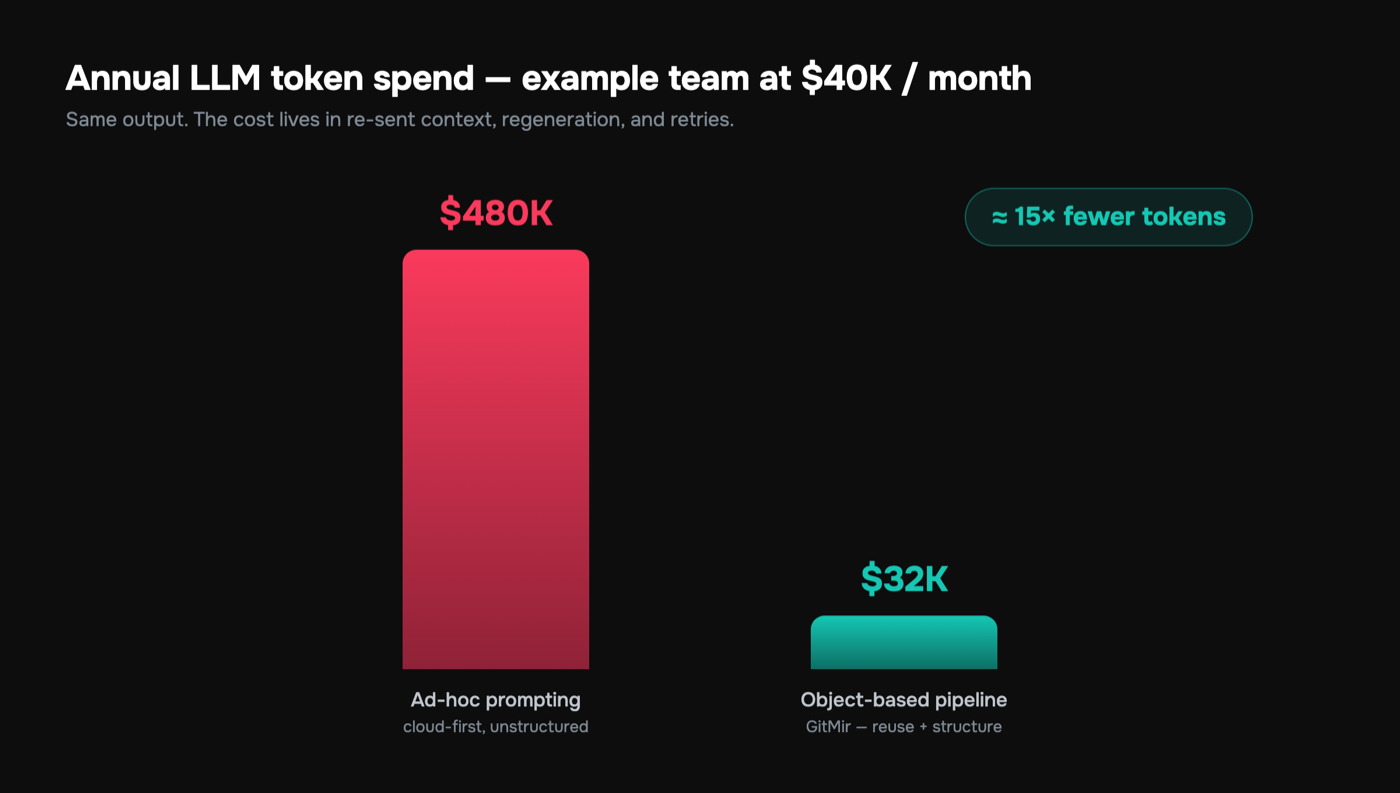
A realistic before/after
Here's a mid-size feature on a 50k-LOC codebase, done the ad-hoc way versus the scoped way. The numbers are illustrative, but the ratios are what I see repeatedly in real workflows.
| Approach | Input tokens | Output tokens | Repair rounds | Relative cost |
|---|---|---|---|---|
| Ad-hoc prompting (whole-file attach, re-send on every turn) | ~157,000 | ~5,400 | 4 | 1.0x (baseline) |
| Scoped + cached context, validated objects | ~10,500 | ~4,900 | 0–1 | ~0.07x |
Same feature. Same model. The output is nearly identical in size — you kept roughly the same amount of code. The 15x delta is entirely on the input side: not re-sending stable context, not re-generating things that already exist, and not paying for repair rounds that never happen because the output was structurally valid the first time.
How to cut LLM token costs: the four levers
You can reduce AI/LLM token costs with four techniques, ordered roughly by impact. None of them require a more expensive model. Most of them work better on cheaper models, because the context is cleaner.
1. Cache the stable context so you pay for it once
Most of what you send every turn doesn't change: system prompts, conventions, type definitions, the schema, the unchanging parts of the files in play. Prompt caching lets the provider store that prefix and bill you a fraction of the price to reuse it across calls within a window.
Anthropic's prompt caching documentation describes cache reads priced at a small fraction of base input cost, with the cache write paid once. The practical effect: in a multi-turn session where 80% of your input is stable, caching can cut the effective input price of that portion by roughly 90%. The discipline is simple — put everything stable at the front of the prompt, everything volatile at the back, and let the cache cover the prefix. Reshuffle context order every turn and you get cache misses and pay full freight. Consistency is what makes the cache pay off.
2. Retrieve the slice, not the file
Sending whole files because "the model might need them" is the single biggest source of waste. A model fixing a function in a 600-line file does not need the other 580 lines. It needs that function, its callers, its types, and its contract. Scoped retrieval means you send the relevant slice of the system, not the buildings around it.
- Function/symbol-level context instead of file-level: pull the unit and its immediate dependencies.
- Dependency-aware selection: include what the change touches, derived from the actual structure, not a fuzzy similarity search that drags in lookalikes.
- No "just in case" attachments. Every file you add hoping it helps is tokens you pay on every subsequent turn it lingers in context.
The catch with retrieval is precision. Naive vector search over an unstructured codebase often retrieves the wrong slice and forces a repair round anyway. Retrieval is only cheap when the system has a real structure to retrieve from — which is the whole argument for modeling architecture explicitly rather than leaving it implicit in a pile of files.
3. Reuse components instead of regenerating them
The cheapest token is the one you never spend because the work already exists. If your auth flow, your data table, your payment webhook handler were generated and validated once, the next feature that needs them should reference them — not regenerate a fresh, slightly-different version that the model improvises from the prompt.
Ad-hoc prompting regenerates constantly. Ask three times for "a form that posts to the orders API" and you'll get three subtly different forms: three generations, three reviews, three chances to drift. A system with reusable, validated components turns that into one generation and two references. Multiply across a real product and component reuse alone is a large chunk of the token savings, and it kills the architectural-divergence problem at the same time.
4. Constrain output so the model writes less
Open-ended generation produces verbose, hedged, re-explained output. Constrained generation — "fill this typed object," "implement this interface," "produce only the diff" — produces tight output and, more importantly, fails closed when it can't comply, instead of confidently producing something wrong that triggers a repair loop. Smaller, structured output is cheaper directly and cheaper downstream.
The four levers compound. Caching, scoped retrieval, reuse, and constrained output aren't four small wins — they multiply, which is how you get from "save 30%" to "spend 15x less."
Why architecture-first generation makes the savings automatic
You can hand-implement all four levers yourself. Carefully order your prompts for cache hits, manually attach only the relevant slices, keep a library of snippets, ask for diffs. It works — until it doesn't, because doing it by hand is exactly the discipline that erodes under deadline pressure. The session where you're tired and just paste the whole file is the session where the bill spikes.
The durable fix is to make the savings a property of the system rather than a habit of the operator. That's what AI-native, architecture-first development does. Instead of the model reconstructing your architecture from files on every prompt, the architecture is already modeled — modules, data flows, APIs, business logic exist as explicit objects. The model generates inside that model.
This changes the token economics structurally:
- Context is bounded by design. Generating an object means sending that object's contract and its immediate dependencies — never the whole codebase — because the structure tells the system exactly what's relevant. Scoped retrieval stops being a thing you remember to do and becomes the only thing that happens.
- Validation happens before deploy, not after a failed run. Output is checked against the model's structure, so structurally invalid generations are caught at the source. Repair loops — the silent token multiplier — largely disappear.
- Components are reusable by construction. A validated object is referenced, not regenerated. The model never re-improvises something that already exists.
This is the mechanism behind GitMir's roughly 15x fewer tokens than ad-hoc prompting for equivalent work. It isn't a discount on the model. It's the elimination of the four wastes above by design. You can see the modeling-and-generation loop on a real example in the product walkthrough, and the GitMir IDE is free to start with one product and one agent. If you want the savings turned into your actual numbers, the ROI calculator does that math directly.
What the research says about the bigger picture
It's tempting to optimize tokens in a vacuum, but the token bill is the small number — engineering time is the big one, and the two are linked. Research from McKinsey on generative AI in software engineering found that AI tools can help developers complete certain tasks meaningfully faster, but the productivity gains shrink or reverse on complex, high-context work — precisely the work where context over-fetch and repair loops dominate. The same conditions that blow up your token bill also blow up your engineering hours.
There's corroborating evidence on the quality side. Research from Gartner on AI in software engineering points to the maintainability and rework risk that surfaces when AI-generated code is adopted without governance — code that gets rewritten shortly after it's written, and similar logic reproduced instead of reused. Both are token-cost problems wearing a quality-problem costume. Rework is repair loops; duplication is the regeneration tax. Reduce one and you reduce the other.
If your only lever for cost is "use a cheaper model," you've capped your savings at the price difference between models. If your lever is "stop re-deriving and re-generating your system," your savings scale with the size of your codebase — and they show up in engineering hours too, not just the API dashboard.
The broader argument for treating this as an engineering-leadership decision rather than a billing footnote is in AI development for CTOs — the token line is a leading indicator of how much re-work your AI workflow is silently generating.
How the tools compare on token efficiency
Most AI coding tools weren't designed around token efficiency. They were designed around developer experience, which is a different objective. Here's an honest read, by category, of where the tokens go.
Editor assistants — Cursor, GitHub Copilot. Excellent at autocomplete and in-editor edits. But you hold the architecture in your head, and the agent reconstructs context from files on each request. Copilot's inline completions are cheap per-keystroke; the cost climbs sharply once you move to multi-file agentic edits where whole files get attached and re-sent. They give you control over context, which means the efficiency depends on your discipline.
App generators — Lovable, v0, Replit Agent, Bolt. Generate working apps from a description, fast. The structure stays implicit, so as the project grows the model re-reasons over more and more of the app on each change, and divergence creeps in — which means regeneration and repair. Great for the first 80% of a prototype. The token-per-change curve bends upward as the system gets real. We compare these head-to-head on the comparison page.
Visual/no-code platforms — Bubble. Bubble isn't LLM-token-priced at all in the same way; its cost model is workload units and plan tiers. Worth naming because if you only care about avoiding LLM tokens, no-code sidesteps them — at the cost of the flexibility and code ownership a real codebase gives you.
Architecture-first generation — GitMir. Bounds context by modeling structure explicitly, validates before deploy, and reuses components — which is what produces the ~15x token reduction. The tradeoff is that you invest in modeling the architecture up front instead of improvising it. For throwaway prototypes that's overhead; for anything you'll maintain, it's the cheaper path quickly.
There is no universally "right" tool here. For a weekend prototype, an app generator's token cost is irrelevant — you'll throw it away. For software you'll maintain and grow, the tool whose token cost doesn't scale with codebase size is the one that wins the second-year budget.
A practical 30-day plan to cut your token bill
You don't need to re-platform to start saving. Here's a sequence that captures most of the savings without a big bet.
- Instrument first. Pull your last month of token usage and split input from output. If input is more than ~90% of total, you have a context-re-sending problem, and everything below applies directly.
- Reorder for caching. Put stable context (conventions, schema, types) at the front of every prompt and keep that order consistent. Turn on prompt caching if your provider supports it. This alone often cuts effective input cost 30–50% in multi-turn sessions.
- Stop whole-file attachments. For one week, force yourself (or your tooling) to attach only the function and its direct dependencies. Watch the per-feature token count drop and notice that output quality usually improves because the context is cleaner.
- Build a reuse habit. Identify the five components your team regenerates most. Validate one canonical version of each and reference it instead of re-prompting. Kill the regeneration tax on your highest-frequency patterns.
- Measure the repair rate. Count how many features need a re-prompt because the first generation failed. That number is your repair-loop tax. If it's high, the fix isn't more prompting — it's validating output against a real structure before you run it.
- Then evaluate architecture-first. Once you've squeezed the manual levers, model one bounded subsystem — billing, notifications, an admin panel — as explicit architecture and generate into it. Compare token spend and repair rate against the hand-tuned version. That comparison is the honest test of whether the ~15x is real for your stack.
Do it in this order because steps 1–5 are free and immediate, and they also prove where your tokens are going — which makes the case for step 6 with your own numbers instead of a vendor's.
The one-sentence version
You reduce AI/LLM token costs in development by ending the cycle of re-sending and re-generating your system on every prompt: cache the stable context, retrieve only the relevant slice, reuse validated components, and constrain output — or adopt an architecture-first system that does all four by construction and gets you to roughly 15x fewer tokens. The model isn't the expensive part. Re-deriving an architecture nobody wrote down is.
If you want to see what that's worth for your team in dollars, the ROI calculator turns the token-and-hours story above into your actual numbers, and the product walkthrough shows architecture-first generation — bounded context, validation before deploy, reusable components — running on a real example. Start with whichever answers the question you're actually asking: what would this save me, or how does it actually work.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
How do I reduce LLM token costs in AI-assisted development?
Stop re-sending and regenerating your system on every prompt. Cache the stable context so you pay for it once, retrieve only the function and dependencies a task touches instead of whole files, reuse validated components rather than regenerating them, and constrain output. These four levers compound, and together they typically cut input token spend by roughly an order of magnitude.
Are input or output tokens the bigger cost in AI coding?
Input tokens, by a wide margin — usually 20x to 50x the output volume in agentic coding. The model receives your prompt, several whole files, conventions, prior turns, and error messages on every call, then emits only a few hundred lines back. The expense is re-reading context, not writing code, which is why scoped retrieval and caching matter most.
Does using a cheaper model meaningfully lower my AI token bill?
It helps, but it caps your savings at the price gap between models — usually well under 2x. Changing how context flows saves far more: caching, scoped retrieval, and component reuse routinely cut spend around 15x. Cheaper models actually perform better on clean, bounded context, so the structural fixes and a smaller model stack rather than compete.
How does GitMir achieve up to 15x fewer tokens than prompting?
By modeling architecture explicitly so the AI generates inside a controlled system instead of re-deriving structure from files each time. Context is bounded to the relevant object and its dependencies, output is validated before deploy so repair loops largely disappear, and validated components are reused rather than regenerated. Those eliminations multiply into roughly a 15x reduction for equivalent work.
Why do repair loops increase token costs so much?
Because every failed generation gets fed back with full context plus the error, costing nearly as much as the original request. Two or three repair rounds — common when the model works blind on non-trivial features — can triple a feature's token cost without shipping any extra code. Validating output against a real structure before you run it removes those rounds at the source.
Is reducing token costs worth the effort if my AI bill is only a few hundred dollars?
Yes, because the token bill is a leading indicator of a much larger hidden cost. The same context over-fetch and repair loops that inflate tokens also burn engineering hours re-deriving and re-fixing the system — often many times the token cost. Cutting tokens usually means cutting re-work, so you optimize the API dashboard and the payroll line at once.

Related articles

The Hidden Cost of Vibe Coding at Scale
Vibe coding feels free — until you count the rework, the token bills, the onboarding drag and the rewrites. Here's the real cost, and how to keep the speed without it.

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.

The Laptop Did Not Just Change. The AI Development Model Changed.
NVIDIA's Spark and the AI PC signal a shift: AI agents are moving onto the machine — always-on, local, next to your code. Why that makes architectural visibility non-negotiable.