
What Is AI-Native Development? A Plain-English Guide
AI-native development means building software where AI is the primary builder and humans direct, review and architect. Here's what changes, what stays, and how to do it without losing control.
AI-native development is a way of building software where the AI isn't a bolt-on autocomplete next to your editor. It's the primary author of the code, working inside a structure you design and control. You stop writing most lines by hand. You model the product, define the architecture, and the AI generates the implementation against that architecture. It's the same shift cloud-native made a decade ago. Not "the old thing plus a new feature," but a different default for how the system gets built from the first commit.
The distinction matters because most teams today are doing AI-assisted development and calling it AI-native. They've bolted Copilot onto VS Code, or they prompt Cursor for a function here and there. That's faster typing. AI-native development is a different animal: the AI builds whole modules, data flows, and business logic, and the human job moves up the stack to defining intent, reviewing structure, and validating output. The keyboard stops being the bottleneck. Judgment becomes one.
Here's the honest version of why this matters. AI can now produce plausible code faster than any human can read it, and plausible is not the same word as correct. The teams winning with AI-native development aren't the ones prompting hardest. They're the ones who handed the AI a system to build inside, so its output is constrained, validated, and reusable instead of a growing pile of confident guesses. This guide walks through what AI-native development actually is, how it differs from vibe coding and AI-assisted coding, what breaks when you do it wrong, and what the toolchain looks like when you do it right.
What "AI-native" actually means (and what it doesn't)
The word "native" is doing real work here. A cloud-native app isn't a desktop app you moved to a server. It was designed around horizontal scaling, statelessness, and managed services from the start. AI-native development is the same kind of redefinition. The process is designed around the assumption that an AI writes most of the code, and humans operate at the level of architecture, intent, and verification.
That gives you a clean three-tier ladder of how AI shows up in a codebase:
- AI-assisted coding — You write code; the AI speeds up the parts you'd type anyway. Copilot's inline suggestions, Cursor's tab-completion. The human is still the author. The AI is a power tool.
- Agentic / vibe coding — You describe a goal in natural language; an agent like Lovable, v0, or Replit Agent writes multiple files and iterates on its own. The AI is the author, but it also invented the structure — usually with no plan you can see or control.
- AI-native development — The AI is the author and it builds inside an architecture you defined first. Intent flows down from a model of the product; code flows up, validated against that model before it ships.
AI-assisted coding makes you type faster. AI-native development changes who writes the software — and moves the human job from authoring lines to authoring structure and verifying results.
Most teams fall into the same trap: they assume AI-native just means "use the agent more aggressively." It doesn't. Crank the autonomy without giving the model a system to build inside and you get the failure mode everyone now recognizes. A demo that worked on Friday, and an incident that wakes you up on Tuesday.
Why this is a real shift, not a buzzword
There's a fair amount of marketing noise around "AI-native," so the claim is worth grounding. The shift is real because the economics of writing code changed. When generating a working CRUD endpoint costs thirty seconds instead of thirty minutes, the scarce resource stops being typing and becomes correctness and coherence at scale. Any process built around the old scarcity — humans hand-typing implementation — now optimizes the wrong thing. AI-native development is what you get when you redesign the process around the new scarcity.
The trust gap is the whole problem
Here's the data point that frames everything. According to McKinsey research on generative AI and developer productivity, the large majority of developers are already using or planning to use AI tools in their workflow — yet only a minority fully trust the accuracy of what those tools produce, and many remain actively skeptical. Adoption raced ahead of trust. People are shipping code they don't fully believe in.
That gap is the design problem AI-native development has to solve. If you can't trust the output, you have three options. Read every line yourself, which throws away the speed. Ship it and hope, which is how production breaks. Or build a system that makes the output trustworthy by construction. Only the third option scales.
Adoption is at 76%. Trust is at 43%. Closing that 33-point gap — not generating more code — is the actual job of AI-native tooling.
Think about what "trustworthy by construction" requires. The AI can't invent a data model that contradicts the one you already have. It can't wire an API call to an endpoint that doesn't exist. It can't quietly duplicate a component that's already in your system. None of those constraints come from a better prompt. They come from generating code inside an architecture the AI is forced to respect.
AI development vs. vibe coding vs. AI-native: a clear comparison
These terms get used interchangeably and they shouldn't. Here's the structured breakdown.
| Dimension | AI-assisted coding | Vibe coding | AI-native development |
|---|---|---|---|
| Who writes the code | Human, AI suggests | AI, from prompts | AI, inside your architecture |
| Where structure comes from | Human, by hand | AI improvises it | Human models it first |
| Human's main job | Authoring | Prompting & accepting | Designing intent + validating |
| What you can see | The code | The output | The architecture and the code |
| Validation | Tests you write | Vibes / "it ran" | Built in, before deploy |
| Reuse | Manual | Rare — duplication is default | Reusable components by design |
| Best for | Daily engineering | Prototypes, demos | Production systems built fast |
The row that matters most is "where structure comes from." Vibe coding — a term Andrej Karpathy coined in early 2025 for "fully giving in to the vibes" and barely reading the diffs — lets the model improvise the architecture prompt by prompt. Fine for a weekend prototype. A slow-motion disaster for anything real, because the model has no memory of the decision it made three prompts ago and a structural bias toward writing more code to satisfy the literal request.
AI-native development keeps the speed of letting AI write everything, but takes the architecture decision away from the model and hands it back to you. You define modules, data flows, APIs, and business logic visually. The AI generates editable objects inside that structure. Same velocity, completely different blast radius when something's wrong.
Why architecture is the load-bearing wall
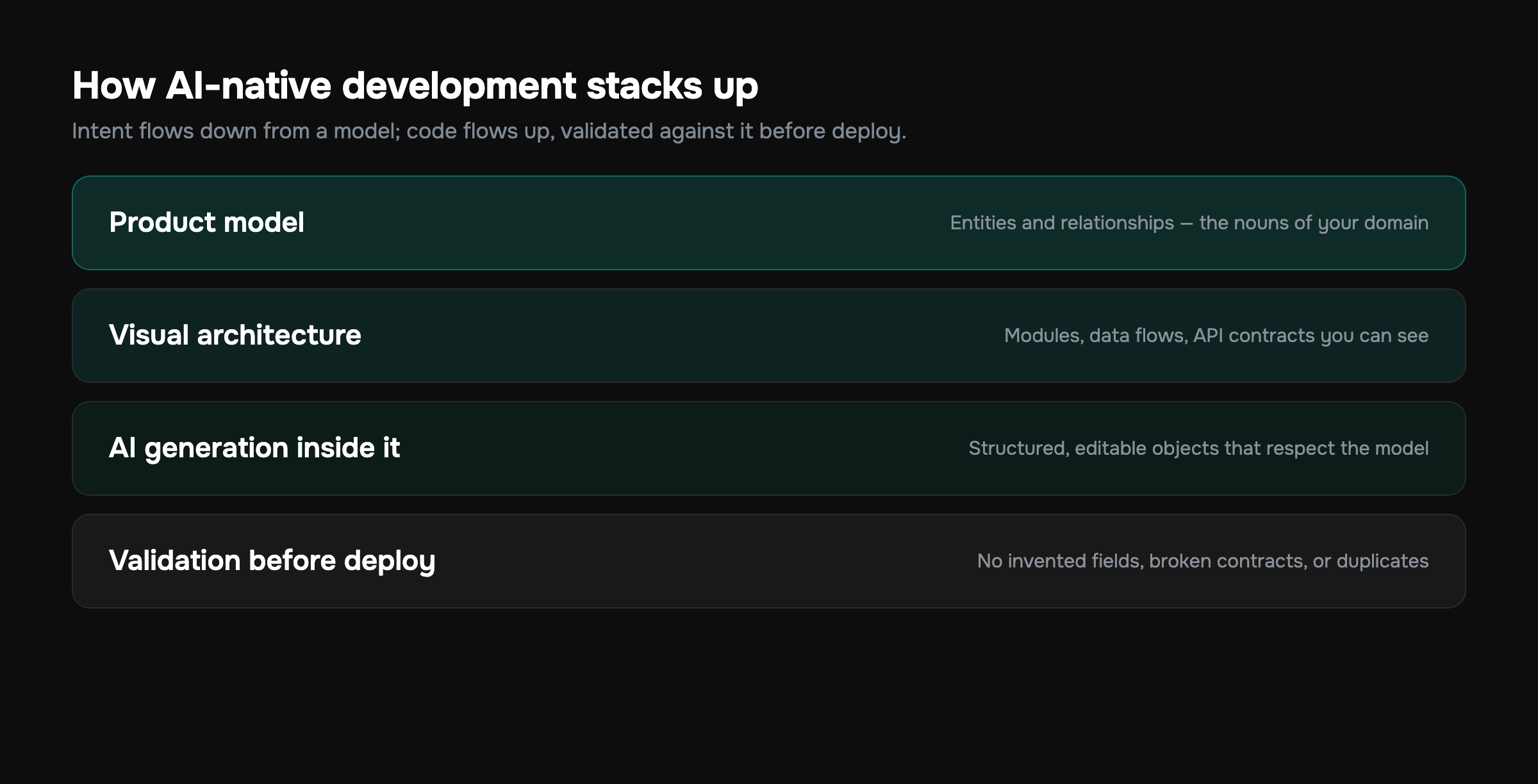
If there's one idea to take from this article, it's this: in AI-native development, architecture stops being documentation and becomes the control surface.
In a hand-coded world, architecture is a diagram on a wiki that's out of date the week after you draw it. The real architecture lives implicitly in the code and in the heads of the senior engineers. That's already a problem for onboarding and maintenance. With AI writing the code, it becomes a critical failure: the model has no head to hold the implicit architecture in. Every prompt is a fresh start with no memory of the whole.
So AI-native development inverts the relationship. The architecture becomes the source of truth that the AI generates from, not an artifact it produces as an afterthought. Concretely, that means:
- You model the product first — entities, relationships, the actual nouns of your domain.
- You build visual architecture — modules, data flows, API contracts, business logic, laid out so you can see the system, not just read files.
- The AI generates inside it — structured, editable objects that respect the model, not free-floating files that might or might not fit.
- Everything is validated against the architecture before deploy — type mismatches, broken contracts, and orphaned references get caught by construction, not in production.
This is the core of how GitMir approaches AI-native development. You build software you can actually see, and the AI works as a generator inside that visual system rather than a black box you hope got it right. We wrote a deeper piece on the philosophy in build software with AI you can see. The visual architecture isn't decoration. It's the thing that makes the AI's output controllable.
What "validated before deploy" buys you
The skeptical-developer half of that adoption-versus-trust stat has a point: unvalidated AI code is a liability. Validation before deploy is what converts AI output from "plausible" to "trusted." When generation happens inside a known architecture, the platform can check that:
- Generated code matches the data model you defined (no invented fields, no type drift).
- API calls point at endpoints that actually exist with the right shape.
- New logic doesn't silently break a contract another module depends on.
- A component isn't being duplicated when an equivalent one already exists.
None of that is possible when the AI improvises structure on the fly, because there's no architecture to validate against. That's the practical difference between AI-native development and aggressive vibe coding. For the deep dive on the validation layer specifically, see how to validate AI-generated code.
The token problem nobody mentions in the demos
There's an economic reality under AI-native development the smooth product demos skip. Tokens cost money and context windows are finite. Every time you prompt an AI to build a feature with no shared structure, you re-send context — "here's the codebase, here's the data model, here's the convention" — over and over. It's wasteful, and it gets more wasteful as the system grows.
When the AI generates inside a defined architecture, it doesn't have to rediscover your system on every prompt. The structure is the shared context. In GitMir's case, that's where the claim of up to ~15x fewer LLM tokens than ad-hoc prompting comes from: you're not re-explaining the world to the model each time, because the model operates against a structure that already encodes it.
That's not a minor line item. At scale, token efficiency is the difference between AI development being a sustainable default and being a budget line your CFO flags. We broke the math down in reduce AI token costs, and you can model it directly for your own team with the ROI calculator.
The cheapest token is the one you never send. AI-native development wins on cost not by using a cheaper model, but by giving the model a structure so it stops re-learning your system on every prompt.
A realistic scenario: shipping a billing feature
Abstract definitions only get you so far. Here's the same task — adding usage-based billing to a SaaS product — done three ways.
The vibe-coding version. You prompt an agent: "Add metered billing with Stripe, usage tracking, and an invoice page." It produces fifteen files in two minutes. It works in the demo. Then you find out it created a second User model because it didn't know about your existing one, the usage counter resets on deploy because it stored state in memory, and the invoice total double-counts because two functions both apply tax. You spend two days untangling code you didn't write and don't fully understand.
The AI-assisted version. You write the architecture yourself, then use Cursor to fill in functions. It's correct and coherent because you held the structure in your head — but you wrote the hard parts by hand, so you captured maybe 30% of the speed AI promised. You're the bottleneck again.
The AI-native version. You extend your existing visual model: add a UsageEvent entity, wire it to the Subscription you already have, define the billing module's data flow and the invoice API contract. The AI generates the implementation inside that structure. It can't invent a second User, because the User is already in the model. The invoice math validates against a single source of truth. You get most of the vibe-coding speed with none of the two-day cleanup, because the architecture refused to let the model improvise the parts that matter.
That third path is what AI-native development is for. The velocity of letting AI build, with the guardrails that make the output something you'd actually put in front of real users and real money.
The honest tradeoffs
AI-native development is not free of cost, and pretending otherwise is how vendors lose credibility. The real tradeoffs:
- Up-front modeling. You have to define architecture before you generate, which feels slower than typing a prompt and hitting go. It pays back within the first refactor, but the first hour is more deliberate than vibe coding's instant gratification.
- A learning curve for the mental model. Engineers used to authoring code have to adjust to authoring structure and reviewing output. It's a genuine shift in where your attention goes, and not everyone adapts on day one.
- You're still on the hook for intent. The AI can't decide what the product should do. Garbage architecture in, garbage system out — faster than ever.
What you get back: code generated at AI speed that's coherent, validated, reusable, and visible. For most teams shipping production software, that trade is overwhelmingly worth it. For a one-off throwaway prototype, pure vibe coding is honestly fine. Use the right mode for the stakes.
How AI-native development changes the team
This isn't just a tooling change. It reshapes who does what. When the AI writes implementation, the leverage moves to whoever can design good architecture and verify output fast. That has real org consequences.
Junior engineers stop spending their first six months learning to type idiomatic code and start learning to read and validate systems earlier — which is the more valuable skill anyway. Senior engineers and CTOs get a force multiplier: their architectural judgment, historically locked inside code review and design docs, becomes the literal input that drives generation. We wrote a whole piece for technical leaders thinking through this transition in AI development for CTOs.
The flip side is real, and worth naming. Research from Google's DORA "State of DevOps" program has found that while AI adoption boosts individual throughput, it can pressure software delivery stability — exactly the "more code, less coherence" failure mode you'd predict when generation outpaces structure. AI-native development is, in large part, a direct answer to that finding. Reusable components and a single architectural source of truth are how you generate a lot of code without generating a lot of duplication.
The toolchain: where each tool actually fits
No single category covers everything, and an honest map helps you pick. Here's where the major players sit relative to AI-native development.
- Cursor / GitHub Copilot — Best-in-class AI-assisted coding. They make authoring faster inside your editor and you keep full control of the code. They do not give you a visual architecture or validation layer; structure is still entirely on you.
- Lovable / v0 / Replit Agent — Excellent agentic builders for getting from prompt to working app fast. The speed is real and the demos are honest about velocity. The gap is control: the architecture is improvised, mostly invisible, and hard to govern as the app grows past a prototype.
- Bubble — A mature visual builder, but no-code rather than AI-native — you assemble logic by hand in their editor rather than having AI generate it, and you're inside their runtime.
- GitMir — Visual architecture plus AI generation inside it, with validation before deploy and reusable components. The bet is that AI-native means "AI builds inside a controllable visual system," not "AI improvises and you hope."
You don't have to pick a single tool religiously. Plenty of teams use Copilot for in-editor assist and an AI-native platform for building whole features. If you want a side-by-side on where these land for your specific situation, the comparison page lays it out, and the GitMir IDE lets you try an AI-native workflow free instead of burning tokens on ad-hoc prompting.
How to tell if you're ready for AI-native development
A quick self-check. You're a good candidate if:
- You're already using AI to write real code — not just experimenting, but shipping with it, and feeling the trust gap firsthand.
- You've been bitten by AI-generated mess at least once — the duplicated model, the silent contract break, the feature that worked until it didn't.
- You care about the system in six months, not just the demo on Friday — you're building something people will depend on.
- Your bottleneck is coherence, not typing speed — you can generate code fast already; keeping it consistent is the hard part.
Nodded at three of those? Then you're past the point where AI-assisted autocomplete is enough and squarely in the territory AI-native development was built for. The question isn't whether AI writes your code — it already does or soon will. The question is whether it writes that code inside a system you control, or improvises in the dark and hands you the cleanup.
The next step
AI-native development comes down to one decision: do you let AI generate code inside an architecture you can see and validate, or do you let it improvise and hope? The first path gives you the speed without the 2 a.m. incident. The second gives you a great demo and a growing pile of invisible debt.
If you want to put real numbers on the difference for your team — token spend, cleanup time, velocity — run your own figures through the ROI calculator. If you'd rather just see what "AI building inside a visual architecture" looks like in practice, take a look at the product. Either way, the move is the same: stop letting the model improvise the structure, and make it generate inside one you control.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
What is AI-native development?
AI-native development is building software where AI writes most of the code inside an architecture you design and control, rather than as a bolt-on autocomplete. You model the product and define the structure; the AI generates validated, reusable code inside it. The human job shifts from authoring lines to authoring intent and verifying output.
What is the difference between AI-native development and vibe coding?
Vibe coding lets the AI improvise the architecture prompt by prompt, which is great for prototypes but accumulates invisible debt fast. AI-native development keeps the speed of AI-written code but takes the structure decision back from the model — you define the architecture first, and the AI generates inside it, validated before deploy.
Is AI-native development the same as AI-assisted coding?
No. AI-assisted coding — like Copilot or Cursor autocomplete — means you author the code and AI speeds up the typing; you stay the author. AI-native development means the AI is the primary author, building whole modules inside an architecture you defined, while you move up to designing intent and validating the output.
Do developers actually trust AI-generated code?
Not yet, and the data shows it. McKinsey research on generative AI and developer productivity found that the large majority of developers use or plan to use AI tools, yet only a minority fully trust their accuracy. That gap between adoption and trust is precisely why AI-native development emphasizes generating code inside a validated architecture instead of shipping unverified output.
Does AI-native development save money on AI tokens?
Yes, significantly. When AI generates inside a defined architecture, it stops re-sending your whole codebase and conventions on every prompt — the structure is the shared context. GitMir reports up to roughly 15x fewer LLM tokens than ad-hoc prompting, which at scale is the difference between AI development being sustainable or a flagged budget line.
When should I use vibe coding instead of AI-native development?
Use pure vibe coding for throwaway work — prototypes, demos, internal experiments, learning — where speed matters and nobody depends on the result. Switch to AI-native development the moment real users, real money, or long-term maintenance enter the picture, because that's when improvised architecture turns into expensive cleanup and production incidents.

Related articles

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.

The Laptop Did Not Just Change. The AI Development Model Changed.
NVIDIA's Spark and the AI PC signal a shift: AI agents are moving onto the machine — always-on, local, next to your code. Why that makes architectural visibility non-negotiable.