
How to Validate AI-Generated Code Before It Ships
AI writes confident code that's sometimes wrong. A repeatable validation process catches the failures before production. Here's a practical checklist plus the system-level fix.
You validate AI-generated code before it ships by treating the model's output as untrusted input. Not as a senior engineer's pull request you can wave through. That means three layers working together: structural validation (does this code fit the architecture and contracts it's supposed to fit?), behavioral validation (does it actually do what the requirement said?), and human validation (does a person who understands the system's invariants sign off on the diff?). Most teams make one mistake, and it's the same one every time. They jump from "the AI produced something that runs" straight to "ship it." But running and correct are two completely different claims.
Here's the uncomfortable part. AI-generated code is optimized to look right, not to be right. The model is a fluent pattern-matcher producing the most statistically plausible continuation of your prompt, and plausible code passes a glance. It compiles. It often passes the happy-path test you thought to write. Then it silently violates an invariant nobody encoded: calls an API that doesn't exist the way the model imagined, duplicates a validation rule that already lived somewhere else, returns snake_case where the rest of your system speaks camelCase. "Does it run" catches none of that.
So the real question isn't "how do I review AI code faster." It's how do I make wrong code impossible to ship instead of merely unlikely. This article is the practical answer: a validation pipeline you can actually run at the speed AI generates, why the usual review reflexes break under that speed, and where a controlled architecture does the heavy lifting that human eyeballs can't.
Why Validating AI-Generated Code Is Different From Reviewing Human Code
Code review evolved for a world where a human wrote the code. That human held context — your conventions, the reason a module exists, the one billing edge case that bit you last quarter. Review was a sanity check on a colleague who already shared most of your mental model.
AI breaks that assumption completely. Every prompt is a fresh roll of the dice with no memory of the decisions that came before. The model doesn't know your conventions, can't see your whole codebase, and will confidently produce code that violates rules nobody wrote down. You're not reviewing a teammate's work. You're verifying the output of a stochastic process that has zero stake in your system's integrity.
Three things change as a result:
- Volume. A human ships a few diffs a day. An AI-assisted workflow can produce ten or more. Manual review that worked at human speed becomes the bottleneck — or worse, becomes a rubber stamp because nobody can actually read that much code that carefully.
- Failure mode. Human bugs cluster around hard problems. AI bugs cluster around context gaps — the model inventing a plausible answer for the part of your system it couldn't see.
- Consistency. Ask the same model the same thing twice and you can get two different implementations. That non-determinism is exactly what makes duplication and silent contract drift accumulate.
Reviewing AI code with a human-code review process is like inspecting a car coming off a robot assembly line by test-driving every hundredth one. The throughput doesn't match the defect rate. You need validation built into the line, not bolted onto the end.
This is why "prompt better" is the wrong fix. Better prompts reduce the rate of bad output. They don't give you a guarantee, and validation is about guarantees.
The Hard Data: AI Speeds Up Writing and Slows Down Maintaining
Think the risk is theoretical? Look at what's actually showing up in real repositories. Research from McKinsey on generative AI and developer productivity found that while AI tools can substantially speed up how fast code gets written, those gains erode without the right guardrails — and that quality, maintainability, and review discipline determine whether the speedup survives contact with a real codebase. Put plainly: AI assistants make it dramatically faster to add code and quietly make it harder to maintain it.
That's the validation problem in one sentence. The thing AI optimizes — speed of production — is not the thing that determines whether your software survives contact with users. Google's DORA State of DevOps research makes the same point from the delivery angle: AI adoption can accelerate throughput while putting pressure on stability if the surrounding system doesn't enforce quality. The tooling got faster. The need for verification got bigger, not smaller.
The lesson isn't "AI is bad." It's that the cost of skipping validation moved. Pre-AI, sloppy code was slow to produce, so volume was self-limiting. Now volume is nearly free, and the only governor left is the validation you choose to put in front of it.
The Three Layers of Validation Every AI Diff Needs
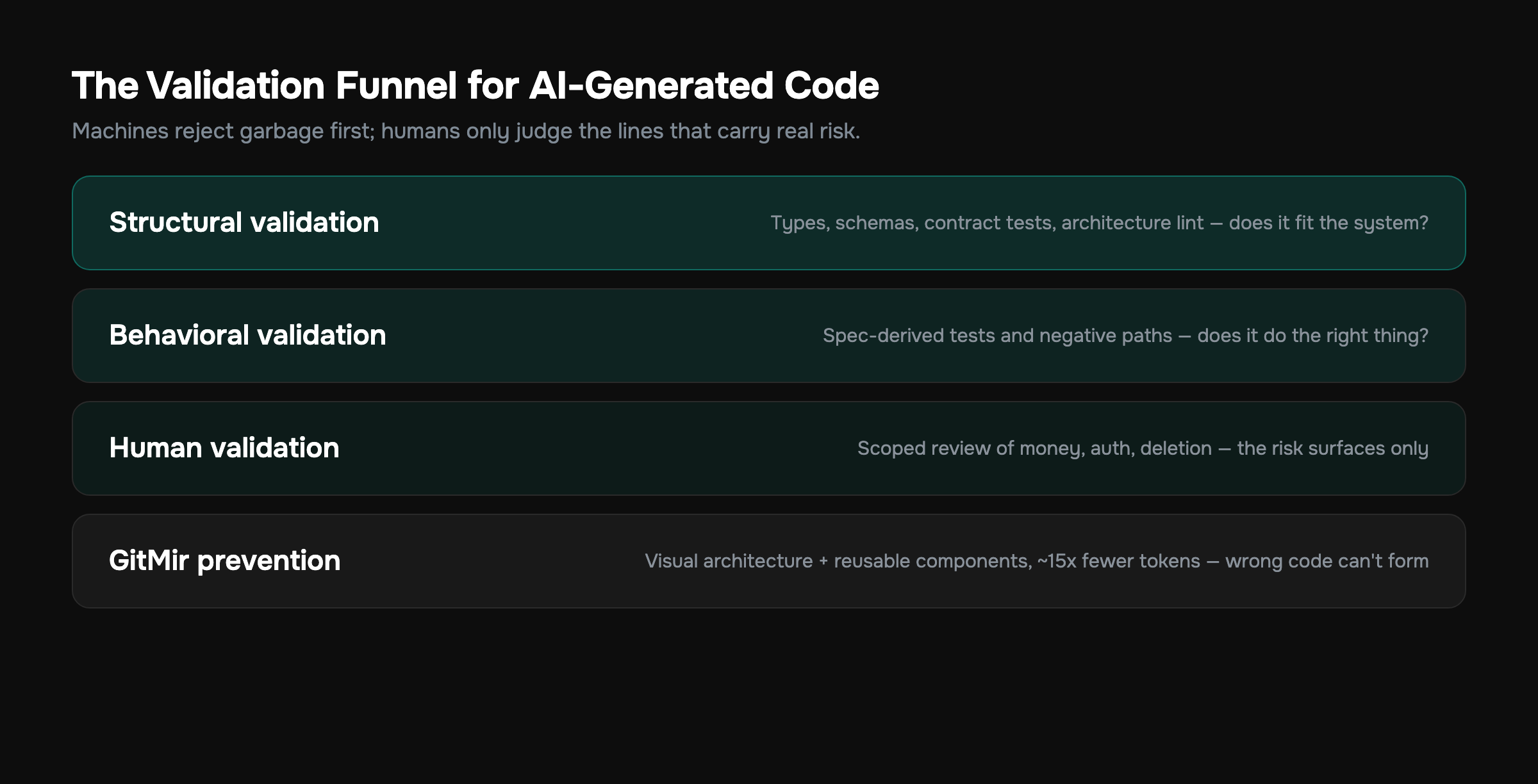
Think of validation as a funnel. Each layer catches a different class of defect, and the order matters because the cheap, automatic layers should reject garbage before a human ever spends attention on it.
Layer 1: Structural validation — does it fit the system?
This is the layer almost everyone under-invests in, and it's the one that matters most for AI code. Structural validation asks: does this code conform to the shape of the system it's joining — its types, contracts, module boundaries, data flows, and naming conventions — regardless of whether it produces the right answer?
Concretely, structural validation includes:
- Type checking and schema validation. Strict TypeScript, a typed API boundary, runtime schema validation (Zod, Pydantic) at the edges. The single highest-leverage move for catching AI hallucinations is making invalid states unrepresentable.
- Contract tests. If the AI touched a service, does its output still match the agreed-upon contract the rest of the system depends on?
- Architecture/boundary linting. Did the AI import across a module boundary it shouldn't? Did it reach into a layer it has no business touching?
- Dependency and API existence checks. Did the model call a function or package that actually exists, with the real signature — not the one it confidently imagined?
Structural validation is where invented APIs and contract drift die. And it's automatable and instant, which is the only kind of validation that keeps pace with AI generation. We go deep on this failure mode in how to do AI coding without hallucinations, but the headline is simple: hallucinations are overwhelmingly a structure problem, and structure is checkable by machines.
Layer 2: Behavioral validation — does it do the right thing?
Once code fits the system, you still have to prove it does what the requirement asked. This is the layer most people call validation. It's necessary but not sufficient.
- Tests written from the requirement, not the implementation. If the AI writes both the code and the tests in the same breath, the tests encode the same misunderstanding. Derive tests from the spec independently — or have a human author the critical ones.
- Edge cases and negative paths. AI is excellent at the happy path and lazy about the empty list, the unauthorized user, the duplicate submission, the timezone. These are where AI code breaks in production.
- Integration tests over unit-test theater. A wall of passing unit tests on AI code can be misleading because the AI may have mocked away exactly the part that's wrong.
Layer 3: Human validation — does someone who owns the invariants agree?
The final gate is a human who understands what the system is for. Not a line-by-line read of a 600-line diff — nobody does that well at AI volume — but a judgment call on the parts that carry risk: business logic, money, auth, data deletion, anything irreversible.
The goal of layers 1 and 2 is to shrink what layer 3 has to look at. If structure and behavior are machine-verified, the human can focus on the handful of decisions that genuinely need judgment instead of drowning in plausible-looking code.
The objective is not "a human reads every line." It's "a human reads the lines that matter, and the rest is guaranteed by the machine." Any process that puts a human in front of unfiltered AI output is going to fail at scale.
A Concrete Validation Pipeline You Can Ship This Week
Here's a pragmatic sequence that works regardless of which AI tool you use — Cursor, Copilot, Claude Code, or an agent like Replit Agent. Each stage is a gate. Fail one and the change goes back, not forward.
- Generate against a spec, not a vibe. Before any code, write down the contract: inputs, outputs, the data shape, the failure cases. This is the artifact you validate against later. Vague prompts produce unvalidatable code.
- Compile and type-check. Non-negotiable, automated, blocking. Strict mode on. If it doesn't type-check, it never reaches a human.
- Lint for architecture, not just style. Boundary rules, import rules, no-duplicate-implementation checks. Style linting is nice; structural linting is what catches AI drift.
- Run schema/contract validation at the edges. Validate every external input and every cross-service output against an explicit schema. Reject silently-wrong shapes here.
- Run the test suite — including tests the AI didn't write. Behavioral proof that it does the right thing, especially on negative paths.
- Security and secrets scan. AI happily hardcodes credentials, disables auth checks "for now," and writes injectable queries. Automate detection.
- Scoped human review of risk surfaces only. Money, auth, deletion, irreversible actions, anything touching customer data. Everything else has already been mechanically validated.
- Deploy behind a flag, then observe. Ship to a slice of traffic, watch error rates and the behaviors your tests couldn't fully cover, then widen.
A realistic scenario
Say you ask your AI tool to "add a discount code to checkout." It produces a clean-looking 200 lines. Watch where each layer earns its keep:
- The type checker catches that it returned a
numberwhere the cart total is aMoneyobject, so a float-rounding bug never reaches prod. - The architecture lint catches that it wrote its own
validateCouponhelper instead of using the one in your pricing module — the duplication that would've silently diverged later. - The contract test catches that it changed the checkout API response shape, which would've broken the mobile client.
- The negative-path test catches that an expired code still applied a discount because the AI checked existence but not expiry.
- The human looks only at the money math and the auth check — two screens, not twenty — and signs off.
Four of five defects caught by machines, instantly, before anyone spent human attention. That ratio is the whole game.
The Faster Validation Loop: Build Structure So Wrong Code Can't Form
Everything above is a detection strategy: find the bad code after the AI writes it. Detection is necessary. But the higher-leverage move is prevention — make the AI generate inside a structure where most of those defects are impossible by construction.
This is the core idea behind GitMir's approach and why it's different from a pure prompt-and-pray loop. Instead of asking a model to free-write code into a folder and then frantically validating the output, you model the product and build a visual architecture first — modules, data flows, APIs, business logic — and the AI generates structured, editable objects inside that architecture. The constraints aren't a prompt preamble the model might ignore. They're the system itself.
What that buys you on the validation front:
- Contracts exist before code does. When the data flows and API boundaries are modeled up front, the AI can't invent an incompatible shape — there's nothing to invent into. Structural validation happens by construction instead of after the fact.
- Reuse is enforced, not hoped for. Because generation happens against reusable components, the AI can't quietly write a fourth
formatPrice. The duplication that industry research shows piling up across AI-assisted codebases doesn't accrete the same way. - Validation runs before deploy, in context. The output is checked against the architecture it lives in, not just against whether it compiles in isolation.
- Up to ~15x fewer tokens. Because the model isn't re-deriving your entire context on every prompt, generation is cheaper and less error-prone — fewer tokens spent guessing means fewer guesses to validate. (We break the economics down in reduce AI token costs and you can model your own savings on the ROI page.)
Detection asks "is this code wrong?" Prevention asks "could this code have been wrong?" The second question is cheaper to answer at scale, because the answer is structural, not case-by-case.
This is where the landscape splits. Tools like Cursor and GitHub Copilot are superb at generating into an existing repo, but they hand you raw output and leave validation entirely to you and your CI. v0 and Lovable get you a working UI fast but don't give you architectural contracts to validate against. Bubble enforces reuse and structure but traps you in a closed visual runtime with no real, editable code to inspect. What's been missing is structure and real code: an architecture that constrains the AI, with output you can still read, test, and own. That's the gap GitMir is built for — see how the pieces fit on the product page and how it stacks up on the comparison page.
What Good Validation Looks Like vs. What Most Teams Do
| Dimension | The common (risky) approach | What actually works |
|---|---|---|
| What you trust | "It runs / the demo worked" | Structural + behavioral + human gates |
| When you validate | After generation, in review | Continuously, with prevention up front |
| Who validates structure | A human skimming the diff | The type system, schemas, and lint rules |
| Tests | Written by the AI alongside the code | Derived from the spec, independent of the code |
| Human attention | Spread across the whole diff | Concentrated on risk surfaces only |
| Duplication control | "We do code review" | Enforced reuse via shared components |
| Deploy | Merge and pray | Flagged rollout with observed behavior |
The left column isn't negligence. It's what a reasonable team does when it ports a human-code process onto AI-speed output. The right column is what survives once you accept that the production rate changed and the validation has to change with it.
Where Validation Most Often Fails in Practice
A few specific traps catch even careful teams:
- The AI writes its own tests. This is the most common silent failure. The tests pass because they were authored to match the (wrong) implementation. Always derive at least the critical tests from the requirement independently.
- Mocks that mock away the bug. Heavy mocking lets AI code "pass" while the real integration is broken. Favor integration tests on anything that crosses a boundary.
- Green CI on a non-deterministic system. AI may have introduced a race or a time-dependent path your suite doesn't exercise. Flag-gated rollout with observation is your backstop.
- Reviewer fatigue. When every PR is 400 lines of plausible code, reviewers stop reading and start approving. If you can't shrink the human's surface area, you don't have a validation process — you have a ritual.
- Context drift over time. Each generation is individually fine but collectively the codebase loses coherence. If you're seeing the warning signs in signs your AI codebase is becoming unmaintainable, validation gaps are usually the root cause.
Not sure how much autonomy to give your tools in the first place? What is an AI coding agent is a useful primer on where agents fit — and where they need the most guardrails.
A Quick Validation Checklist
Pin this somewhere your team will see it before the next AI-generated PR merges:
- Is there a written spec/contract this code is being validated against?
- Does it type-check in strict mode? (blocking)
- Are external inputs and cross-boundary outputs schema-validated?
- Did the architecture lint pass — no boundary violations, no duplicate implementations?
- Are there tests derived from the requirement, including negative paths?
- Did a security/secrets scan run?
- Has a human reviewed the risk surfaces (money, auth, data, irreversible actions)?
- Is it shipping behind a flag with error/behavior observation?
If any answer is "no," the code isn't validated — it's just untested code that happens to run. Those are not the same thing, and the gap between them is exactly where production incidents live.
The Next Step
Validating AI-generated code is not about reading faster or prompting smarter. It's about building a pipeline where wrong code is caught by machines before it reaches a human, and where the architecture itself prevents most of the wrong code from forming in the first place. Detection at the end of the line is table stakes. Prevention built into the line is the unlock.
Is your current loop "AI writes, CI compiles, ship and hope"? The cheapest experiment is to add the structural layer — strict types, schema validation at the edges, architecture linting — and watch how many defects it catches before a human ever looks. If you want to skip ahead to a system where that structure is built in by default, see how GitMir works, run the numbers on what controlled generation saves you, or start free in the GitMir IDE. Validation you can actually run at AI speed is the difference between shipping faster and shipping broken faster.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
How do you validate AI-generated code before deploying it?
Validate AI-generated code with three layers before deploy: structural validation (strict types, schema checks, and architecture lint to confirm it fits your contracts), behavioral validation (spec-derived tests covering negative paths, not just the happy path), and scoped human review of risk surfaces like money, auth, and data. Then ship behind a feature flag and observe before widening rollout.
Can you trust AI-generated code without reviewing it?
No. AI-generated code is optimized to look plausible, not to be correct, and it routinely passes a glance while silently violating contracts or inventing APIs. Treat it as untrusted input: machine-validate structure and behavior automatically, then have a human review the high-risk parts. Never ship purely because the code compiles or the demo worked once.
Why does AI-generated code pass tests but still fail in production?
Usually because the tests were written by the same AI that wrote the code, so they encode the same misunderstanding, and because AI excels at the happy path while ignoring edge cases like empty lists, expired tokens, and timezones. Heavy mocking can also hide broken integrations. Derive critical tests from the spec independently and favor integration tests over isolated unit tests.
What tools help validate AI-generated code?
The most reliable validators are automated and structural: strict TypeScript or typed boundaries, runtime schema validation like Zod or Pydantic, contract tests, architecture and boundary linters, security and secret scanners, and feature-flagged rollouts. Generation tools like Cursor and Copilot hand you raw output to validate yourself, while a controlled architecture like GitMir enforces many structural checks by construction before deploy.
How is reviewing AI code different from reviewing human code?
Human review assumes the author shared your context and conventions; AI shares neither and produces far more code per day. AI defects cluster around context gaps rather than hard problems, and the same prompt can yield inconsistent implementations. So you cannot rely on a human reading every line — you automate structural and behavioral checks and reserve human attention for the genuinely risky decisions.
Does validating AI code slow development down?
Done right, it speeds you up. Manual review of unfiltered AI output is the real bottleneck. Automated structural and behavioral gates reject garbage instantly, so humans only inspect risk surfaces, and generating inside a controlled architecture prevents many defects from forming at all. The slow path is shipping broken code and paying for it later in churn, incidents, and rework.

Related articles

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.

The Laptop Did Not Just Change. The AI Development Model Changed.
NVIDIA's Spark and the AI PC signal a shift: AI agents are moving onto the machine — always-on, local, next to your code. Why that makes architectural visibility non-negotiable.

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.