
What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.
Vibe coding is building software by describing what you want in plain language and letting an AI write the code. You steer with prompts, screenshots, and intuition instead of typing every line yourself. The phrase came from Andrej Karpathy in February 2025, describing a mode where you "fully give in to the vibes" and stop reading the diffs. You talk, the model builds, you ship. One person can now produce in a weekend what used to take a small team a month. That isn't hype. It's just true.
The problem is that the part everyone quotes — "stop reading the diffs" — is the exact mechanism by which vibe coding breaks production. An AI is brilliant at generating plausible code and completely indifferent to whether that code is correct, secure, or consistent with the rest of your system. It has no memory of the decision you made three prompts ago. It has no concept of your data invariants. And it has a structural bias toward writing more code to satisfy the literal request. Leave it unsupervised and you get a stack of works-until-it-doesn't features, assembled by something that can never see the whole.
So here is the answer-first version of "what is vibe coding": it is the fastest way to build software that has ever existed, and the fastest way to accumulate invisible debt if you do it without an architecture to keep the AI honest. This piece covers what vibe coding actually is, the three modes people confuse, where it quietly fails, what the research says about the wreckage, and the part most articles skip — exactly how to keep the speed without the 2 a.m. incident. The short fix: stop letting the model improvise your structure, and make it generate code inside a system you control.
Where the term came from, and the caveat everyone dropped
When Karpathy described vibe coding, he was talking about throwaway weekend projects. Fun, low-stakes, code that "grows beyond my usual understanding." He was explicit that it works precisely because nothing serious depends on it. The internet kept the word and threw away the caveat, then went and applied "vibe coding" to production SaaS handling real users, real data, and real money.
That semantic drift is most of why the term has picked up a bad reputation. Vibe coding was named Collins Dictionary's Word of the Year for 2025, which tells you how fast it spread and how loosely it now gets used. The mode Karpathy described is genuinely great. The mode people are actually doing — pointing throwaway-grade discipline at customer-facing systems — is where the horror stories come from.
The word "vibe" is doing real damage. It implies you can stop thinking. You can stop typing — you cannot stop thinking about structure, or the structure thinks for you, badly.
The three things people call "vibe coding"
Before you can do it safely, you have to notice that one phrase is covering three very different activities with very different risk profiles.
- Pure vibe coding. You never read the code. You prompt, accept, run, re-prompt on errors, repeat. Perfect for prototypes, demos, throwaway scripts, and learning a new framework. Genuinely dangerous for anything users depend on.
- AI-assisted coding. You use Cursor, Copilot, or Claude inside your editor, but you review every change, write tests, and own the architecture. This is just engineering with a much faster autocomplete. The control stays with you.
- Agentic building. A tool like Replit Agent, Lovable, v0, or Bolt takes a high-level goal and builds many files, runs commands, and iterates on its own. The most powerful mode and the easiest to lose the thread of, because reviewing what it did is often harder than writing it would have been.
Most of the pain people blame on "AI coding being bad" is a category error. They used pure vibe coding for a job that needed agentic building with guardrails. The tool wasn't wrong. The mode was wrong for the stakes. And getting the mode right for the stakes is, honestly, ninety percent of doing this well.
Why vibe coding works at all (and why that's also the trap)
It's worth being precise about why this suddenly works, because the mechanism tells you exactly where it breaks.
A large language model is an extraordinary pattern completer trained on essentially all public code. Ask for "a login form with email and password" and the model has seen ten million of them; it produces a clean, idiomatic one instantly. For any task that resembles a well-trodden path, AI is faster than you and often writes tidier code than the median developer under deadline. The leverage is real:
- A CRUD endpoint that took 30 minutes to write takes 30 seconds to generate.
- Boilerplate — forms, validators, API clients, test scaffolds — collapses to near-zero cost.
- The cost of exploring an idea drops to almost nothing, so you try five approaches instead of marrying the first.
That last point is the underrated win. Vibe coding's biggest gain isn't typing speed; it's that experimentation becomes cheap enough to be your default mode. But notice the mechanism. The model is fast because it produces plausible code from local patterns, with no durable model of your specific system. Plausible and correct are different words, and the gap between them is where production breaks. For the full economics of that gap, see the hidden cost of vibe coding.
What the research actually shows
This isn't just vibe (sorry). There's now hard data on what happens to code quality when AI does the writing and humans stop steering the structure.
Research from McKinsey on generative AI and developer productivity found that AI coding tools can sharply accelerate how fast code gets written — but that the speed-up concentrates in routine, well-trodden tasks and shrinks or reverses on complex, unfamiliar work, and that the gains only hold when teams pair the tools with strong review and engineering discipline rather than accepting output unchecked. The pattern they describe is the same one this article is about. AI is fastest at re-deriving familiar code, and when nobody is enforcing structure that speed quietly turns into duplicated, hard-to-maintain code. Generating more lines is easy. Keeping them coherent is the part that breaks.
Duplication is the smoking gun. It's the measurable fingerprint of a system being assembled prompt by prompt, where the model re-derives the same logic instead of reaching for the version that already exists.
Why does this matter beyond aesthetics? Because duplicated code is where bugs breed and where changes go to die. When the same logic lives in six near-identical copies, a fix in one is a missed fix in five. These findings are the statistical shadow of the exact failure mode this whole article is about: vibe coding without enforced structure trades short-term speed for a codebase that gets quietly harder to change. The primary target of "vibe coding" critiques isn't the AI's line-level quality. It's the structural rot that accumulates when nobody owns the architecture.
Where vibe coding quietly breaks production
Here's the part the demos skip. The four most common ways vibe-coded software fails are all architecture failures wearing a coding-failure costume.
The model has no memory of your system
Every prompt is functionally a fresh start. The AI doesn't remember that all money is stored in integer cents, that user_id is a UUID and not an int, or that the orders service is the only thing allowed to write to the inventory table. So it cheerfully stores a price as a float, joins on the wrong key, and mutates inventory directly from the checkout handler. Each piece passes its own little test. The system rots from the seams.
Hallucinated APIs and silent assumptions
Models invent functions, npm packages, and config keys that don't exist — with total confidence. They also make silent assumptions ("the user is always authenticated here," "this list is never empty") that hold in the happy-path demo and explode on real traffic. We dug into taming this in AI coding without hallucinations.
Security is an afterthought by default
Ask for a file upload and you'll get one that works. What you usually won't get: MIME validation, size limits, path-traversal protection, or an auth check, unless you explicitly demand them. The model optimizes for "does the feature work in the screenshot," not "does it survive a hostile user." A steady drip of 2025 incidents involved vibe-coded apps shipping with hardcoded keys, missing authorization checks, and injection bugs the founder never saw — because they never read the code.
The accumulation problem
A single AI-generated feature is almost always fine. The hundredth one, generated without a shared structure, is a haunted house — every room built by a contractor who never met the others. Velocity stays high for weeks. Then a "small" change requires touching six places that should have been one, no one (human or AI) can hold the whole thing in their head, and every fix spawns two regressions. The full version of this failure mode, and how to climb out, is in scaling a vibe-coded prototype to production.
The root cause: improvised architecture
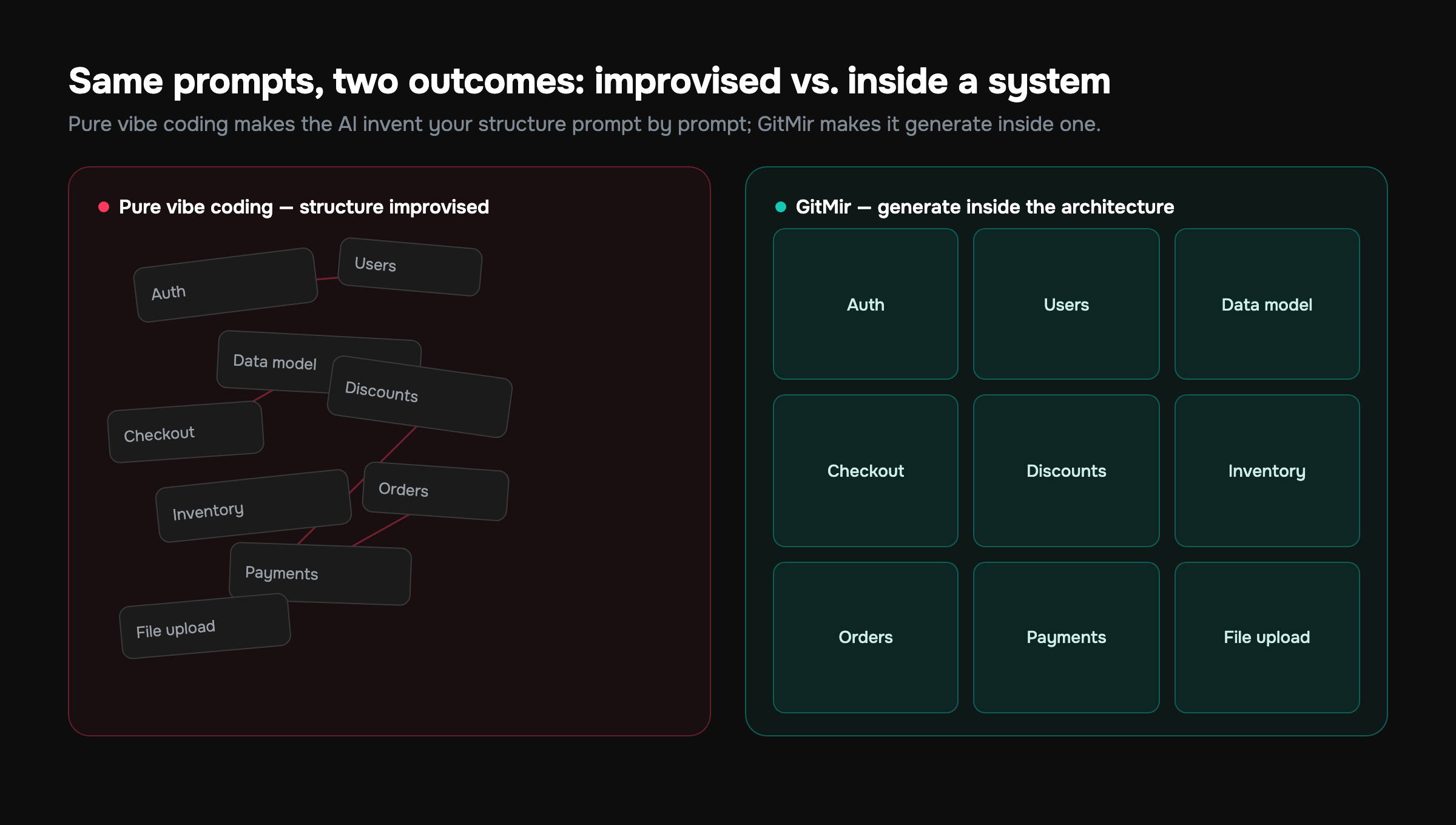
Step back and the pattern is obvious. None of these failures are about the AI writing bad lines. They're about the AI improvising the structure — and structure is the one thing it's worst at, because structure is global and the model only ever sees local context.
Think about how a competent team builds. They agree on a data model. They draw the module boundaries. They decide who owns what, what the contracts between services are, what is allowed to talk to what. Then they write code inside those constraints. Architecture is the thing that keeps a hundred small decisions coherent over time.
Pure vibe coding inverts this. There is no agreed structure; the structure is an emergent, accidental byproduct of whatever the model happened to emit, prompt by prompt. You're asking the AI to be an architect when its entire nature is to be a brilliant, amnesiac contractor. The fix is not "use AI less." The fix is to give the AI the architecture instead of asking it to invent one.
How to vibe code without breaking production
You can keep almost all of the speed and shed almost all of the risk. The principle is one sentence: decide the structure yourself, constrain the AI to generate inside it, and validate before anything ships. Concretely:
- Model the product before you prompt for features. Define your core entities, their fields and types, and their relationships first. Money in cents. IDs as UUIDs. The list of services and what each owns. Twenty minutes here saves twenty incidents later.
- Give the AI the contract, not just the request. Instead of "add a checkout endpoint," hand it the data model, the existing service boundaries, and the validation rules, then ask for the endpoint within those. The narrower the box, the better the output.
- Make boundaries explicit and enforced. "Only the orders service writes inventory" should be a rule the system checks, not a sentence in a Slack message the model never saw.
- Validate before deploy, always. Type checks, schema validation, contract tests, auth checks on every mutating endpoint. The AI is allowed to write the code; it is not allowed to decide the code is correct.
- Reuse components instead of regenerating them. The fifth time you need a form-with-validation, instantiate the same reviewed component — don't roll dice on a fresh generation. This is the direct antidote to the duplication researchers have measured.
- Read the diffs for anything that touches money, auth, data, or external users. You can vibe the marketing page. You may not vibe the payment handler.
Notice how much of this is architecture work the AI can't do for you. And notice how, once it's done, the AI gets dramatically more useful, because it finally has rails.
A concrete scenario: the checkout that almost shipped
Make it real. A founder building a marketplace asks an agentic tool to "add a discount code feature." It generates a clean-looking endpoint, a discounts table, the UI, the lot. The demo works. Ship it Friday.
What the model couldn't see:
apply_discountreads the cart total as a float and rounds inconsistently — off-by-a-cent errors accounting will chase for months.- Nothing checks that a code is still active or under its usage limit, because the prompt never mentioned those rules and the model doesn't know your business.
- The endpoint trusts a client-supplied
final_pricefield. A user with dev tools open buys anything for $0.01. - It writes straight to
orders, bypassing the inventory reservation the rest of the system depends on. Oversold stock.
Every one of these is invisible in the demo and catastrophic in production. And every one is an architecture failure, not a coding failure. Had the model been generating inside a system where money is integer cents, discount validity is a modeled rule, prices are server-authoritative, and order creation must flow through the inventory path, none of these bugs has anywhere to live. The same prompt produces safe code, because the box it was generated in doesn't permit the unsafe version.
Choosing the right tool for the stakes
The market has roughly split into two camps, and picking the wrong one is most of why people get burned.
| Approach | Best for | Watch out for |
|---|---|---|
| Copilot / Cursor | Engineers who own the architecture and review every change | All discipline is on you; nothing enforces structure |
| Lovable / v0 / Bolt | Beautiful front-ends and fast prototypes | Generated structure is improvised; production-readiness is your problem |
| Replit Agent | End-to-end autonomous building and demos | Easiest to lose the thread; reviewing it is harder than writing it |
| Bubble | No-code apps inside Bubble's rails | Real structure, but you're capped by their model and locked in |
| GitMir | Vibe-coding speed with enforced architecture | You do model the system up front — that's the point |
The two extremes both have a flaw. Pure code-gen tools (Cursor, Copilot, Lovable, v0, Replit Agent) give you maximum freedom and zero enforced structure — fast until the accumulation problem hits. Classic no-code (Bubble) gives you structure but caps your freedom and locks you in.
GitMir is built for the gap between them. You build the visual architecture — modules, data flows, APIs, business logic — and the AI generates structured, editable objects inside that architecture, validated before deploy. The model isn't improvising the system; it's filling in a system you defined. And because the structure and reusable components are shared context, the AI stops re-deriving everything on every prompt — in practice up to ~15x fewer LLM tokens than ad-hoc prompting, which is both cheaper and far more consistent. The side-by-side comparison lays out where each tool fits.
The goal was never to write less code. It was to never again ship a feature whose blast radius no one understood.
The trade-offs, honestly
Architecture-first vibe coding is not free. The honest ledger:
- You pay up front. Modeling entities and boundaries before generating features is real work. For a throwaway prototype you'll genuinely never ship, it's overkill — pure vibe coding is the right call there.
- It's less magical to demo. "Watch me describe an app and it appears" is a better video than "watch me model a data schema." The second one is what survives contact with users.
- You have to actually decide things. What owns inventory? Is email unique? The AI will happily decide for you if you don't — and that's the whole problem.
What you get back: features that compose instead of collide, a system that stays in one head past version 50, security and correctness by construction instead of by luck, and a token bill that doesn't balloon as context gets re-sent on every prompt. For most teams building something real, that's the trade of the decade. If you want the math on what rework and incidents actually cost versus the up-front modeling, the ROI calculator puts numbers on it.
Common mistakes (and what to do instead)
- Mistake: shipping code you've never read to production. Instead: vibe the prototype freely, but read every diff that touches money, auth, or data before it goes live.
- Mistake: treating the AI as the architect. Instead: you own the structure; the AI fills it in. It's a contractor, not the foreman.
- Mistake: trusting the happy-path demo. Instead: assume every list can be empty, every input hostile, every user logged out — and make validation catch what the demo hid.
- Mistake: regenerating the same thing repeatedly. Instead: turn anything you've built twice into a reusable component and instantiate it. That's how you stay off the duplication curve.
- Mistake: letting context balloon. Instead: give the model a stable architecture as shared context so it isn't re-deriving your whole system on every request — that's where the token savings and the consistency both come from.
- Mistake: assuming "it runs" means "it's correct." Instead: gate deploys on type checks, schema and contract validation, and auth checks. Running is the floor, not the bar.
So, should you vibe code?
Yes — almost everyone should, and the real question isn't whether but in which mode. For a weekend experiment, a landing page, an investor demo, or learning a new framework: vibe freely, don't overthink it. That's the sweet spot Karpathy actually described.
For anything real users touch — anything handling their data, their money, or their trust — keep the speed but change the mode. Decide the architecture yourself. Make the AI generate inside it. Validate before deploy. Reuse what works. That isn't slower vibe coding; once the rails are up it's faster, because the AI stops generating things you have to rip out.
The future isn't humans writing every line, and it isn't AI improvising whole systems unsupervised. It's humans owning the architecture and AI building inside it at machine speed. That's the bet GitMir is built on — visual architecture, AI under control, validation before anything ships.
If you're deciding whether to keep vibe coding the way you do now or put architecture underneath it, start with two moves: run your numbers on the ROI calculator to see what improvised structure is costing you in rework, and see how the product works to watch AI generate inside a system instead of around it. If you're weighing options, the tool comparison lays out the trade-offs, and the GitMir IDE is free to start when you're ready.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
What is vibe coding in simple terms?
Vibe coding is building software by describing what you want in plain language and letting an AI write the code, instead of typing every line yourself. Andrej Karpathy coined the term in February 2025. It's fastest and safest for prototypes and experiments; for production you keep the speed but add architecture and validation so the AI generates inside a system you control.
Is vibe coding safe for production applications?
Pure vibe coding — accepting AI output without reading it — is not safe for production, because models routinely skip security checks, make silent assumptions, and improvise inconsistent structure. It becomes safe when you define the architecture yourself, constrain the AI to generate within it, and validate every change (types, schemas, auth, contracts) before deploy. The mode matters more than the tool.
Why does vibe-coded software break as it grows?
Each prompt is essentially a fresh start with no memory of earlier decisions, so the model re-improvises structure every time and the pieces drift apart. Industry research has even measured a sharp rise in duplicated code as AI assistants spread. Individually each feature works, but without a shared architecture small changes touch many places and every fix spawns regressions.
What's the difference between vibe coding and AI-assisted coding?
In pure vibe coding you barely read the code and steer entirely with prompts, which is ideal for throwaway projects. In AI-assisted coding you use tools like Cursor or Copilot but review every change, write tests, and own the architecture yourself. The first trades control for speed; the second keeps control and is closer to traditional engineering with faster autocomplete.
How is GitMir different from tools like Cursor, Lovable, or v0?
Cursor, Lovable, v0, and Replit Agent generate code with maximum freedom but no enforced structure, so the architecture is improvised and production-readiness is left to you. GitMir has you build the visual architecture — modules, data flows, APIs, business logic — first, then the AI generates structured, editable objects inside it, validated before deploy. Because that architecture and reusable components are shared context, it also uses up to ~15x fewer tokens.
How do I vibe code without breaking things?
Model your core entities, types, and boundaries before prompting for features; give the AI the data model and rules as context, not just the request; make boundaries explicit and enforced; validate every change before deploy; reuse reviewed components instead of regenerating them; and always read diffs that touch money, auth, or data. Own the structure yourself and let the AI build inside it.

Related articles

What Is AI-Native Development? A Plain-English Guide
AI-native development means building software where AI is the primary builder and humans direct, review and architect. Here's what changes, what stays, and how to do it without losing control.

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.

The Laptop Did Not Just Change. The AI Development Model Changed.
NVIDIA's Spark and the AI PC signal a shift: AI agents are moving onto the machine — always-on, local, next to your code. Why that makes architectural visibility non-negotiable.