
The Hidden Cost of Vibe Coding at Scale
Vibe coding feels free — until you count the rework, the token bills, the onboarding drag and the rewrites. Here's the real cost, and how to keep the speed without it.
Vibe coding feels free. You describe a feature, the model writes it, it runs, you ship. The first ten features land faster than anything you've built before, so you do the math: the cost of vibe coding is the subscription price plus a few API tokens. That math is wrong. And it gets more wrong the larger your system grows. The real cost of vibe coding at scale isn't the generation — it's everything that happens after: the rework, the re-sent context, the silent pileup of duplicated and unreviewed code, and the hours your engineers burn trying to figure out what the AI actually built.
Here's the answer up front. The hidden cost of vibe coding at scale lives in four places. Token spend climbs faster than your feature count, because every prompt re-sends the whole codebase. Code quality degrades as duplication and churn replace refactoring. A maintenance tax lands months later, when nobody — human or model — can explain how the system fits together. And the productivity curve inverts: fast at the prototype, slow and brittle at production scale. None of these show up on the invoice. All of them are paid in real money and real time.
The trap is that vibe coding optimizes for the wrong moment. It makes the first draft cheap and the entire rest of the software lifecycle expensive. A founder shipping a demo never feels it. A team running a 200k-line product on the same workflow feels nothing else. This article is about where that cost actually lives, why it scales nonlinearly, and what changes when AI generates code inside a controlled architecture instead of into an empty file.
What "vibe coding" actually means — and where it breaks
Vibe coding is building software by describing intent in natural language and letting an AI agent produce the implementation, then accepting that output largely on whether it runs rather than on whether it's structurally sound. Andrej Karpathy popularized the term in early 2025, and it captures a real shift: you stop writing most of the code and start steering it. If you want the full background, we covered what vibe coding is in depth elsewhere.
For the first slice of a project, the workflow genuinely earns its reputation. An empty repo has no constraints, no legacy decisions, no cross-module dependencies. The model can hold the entire system in context because the entire system is 800 lines. Cursor, Copilot, Lovable, v0, and Replit Agent all shine in exactly this spot — greenfield, small surface area, fast feedback.
Then you hit a threshold, and it's predictable. Once the codebase outgrows what fits cleanly in context, three things change at once:
- The model can no longer "see" the whole system, so it guesses at interfaces it can't read.
- Every prompt has to re-supply context — files, conventions, prior decisions — because the agent is stateless between calls.
- Generated code stops being net-new and starts colliding with code that already exists, producing duplicates, near-duplicates, and subtle inconsistencies.
Vibe coding doesn't fail loudly. It fails by quietly making each next change a little more expensive than the last, until the curve you thought was linear turns out to be exponential.
That inflection — from "AI is making us 10x faster" to "why does every change take three days" — is the hidden cost arriving on schedule. It's not a tooling bug. It's the structural consequence of generating code into an environment with no enforced architecture.
The token bill that scales with your codebase, not your features
The most measurable hidden cost of vibe coding is token spend, and what surprises people is what it scales with: the size of your system, not the size of your request. You'd expect a small feature to cost a small number of tokens. Instead, a small feature on a large codebase can cost more than a large feature did six months ago.
The reason is mechanical. In an agentic coding session, input tokens dominate output tokens — often by 20x to 50x. To answer even a trivial request, the model receives your prompt plus several whole source files for "context," your conventions, the prior conversation, the last error message, and usually a pile of unrelated code that retrieval swept in to be safe. It writes back a few hundred lines. You paid for tens of thousands of tokens to receive a couple thousand.
Then there's repetition. The agent is stateless, so every turn rebuilds the world from scratch:
- Turn 1: here are 7 files, here's the feature.
- Turn 2: the same 7 files again, plus a type error, please fix.
- Turn 3: same 7 files, now wire it to the API.
- Turn 4: same 7 files, the tests broke, here's the output.
By turn four you've sent the same files four times. The expensive token isn't the one the model writes — it's the one you send for the fourth time because nothing remembered the first three. The bigger the system, the more the agent over-fetches, so the per-feature cost climbs even as your features get smaller.
A second multiplier hides inside that loop: the repair round. When generated code fails to compile, breaks a test, or violates a convention, you feed the failure back in — which means full context again, plus the error, plus a fresh generation. A single repair round can cost as much as the original request. Two or three rounds are routine on any non-trivial feature when the model is working blind. So you've tripled the token cost of a feature without shipping a single extra line.
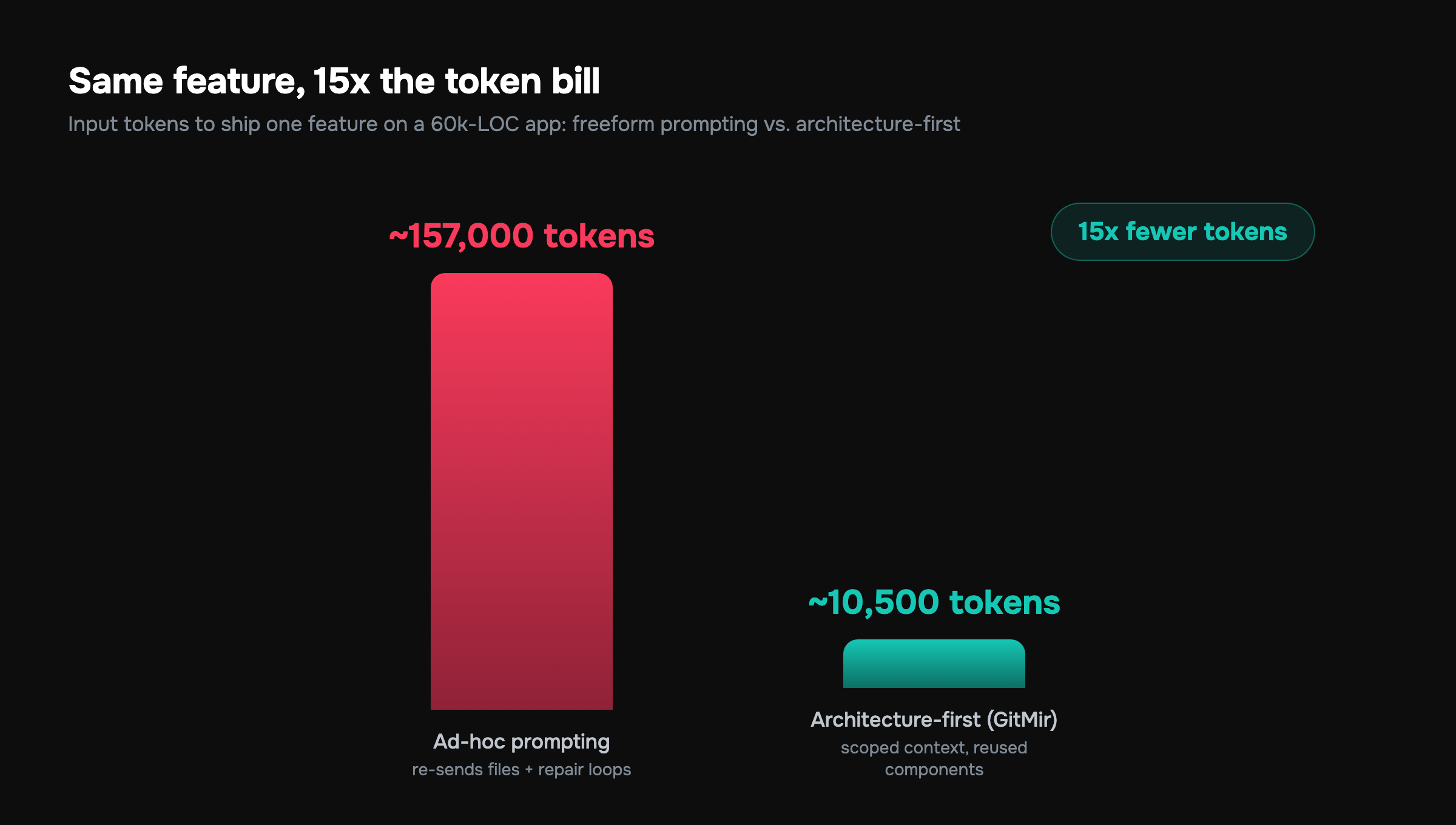
Which is why correctness is a cost-control strategy, not just a quality one. We broke down the dollar mechanics — caching stable context, scoped retrieval, reusing validated components — in how to reduce AI token costs. The headline: the same feature that costs ~157,000 input tokens the ad-hoc way costs closer to ~10,500 when the model regenerates nothing it has already produced correctly and never sees context it doesn't need. That's the roughly 15x gap, and it's entirely on the input side.
The code-quality cost nobody invoices for
The token bill is the visible part. The harder cost is what generated code does to your codebase over time — and here we have data, not vibes.
Research from McKinsey on generative AI and developer productivity points the same way. The tools deliver real speed on contained, well-scoped tasks, but those gains erode sharply on high-complexity work and can reverse without strong engineering discipline around review, testing, and refactoring. Teams report a consistent pattern: as AI assistants went mainstream, fresh generated code increasingly displaced the slower work of consolidating and reusing what already exists. Duplication climbs while the refactoring that would keep a codebase coherent quietly falls away. The speed shows up immediately. The quality cost shows up later.
When refactoring drops and duplication rises, you're not writing software — you're accreting it. Every clone is a future bug that has to be fixed in three places, and a future reader who has to figure out which of the three is canonical.
This is the quiet, compounding tax. AI agents lean hard toward generating fresh code over discovering and reusing what's already there, because reuse demands understanding the existing system and generation doesn't. So instead of calling your existing formatCurrency helper, the model writes a new one inline. Multiply that across a year of features and you get a codebase where the same logic exists in a dozen slightly different forms, none of them authoritative.
The downstream costs are concrete:
- Bug surface multiplies. A fix has to be applied to every copy, and you'll miss some.
- Onboarding slows. New engineers can't tell which implementation is real.
- Refactoring gets dangerous. Touching shared logic means hunting down clones by hand.
- Test coverage erodes. Duplicated logic rarely brings duplicated tests.
We catalogued the warning signs in the symptoms of an AI codebase going unmaintainable. Duplication is usually the first one teams notice, and the last one they connect back to their AI workflow.
The maintenance tax: paying months later for speed today
Generation speed and maintenance cost trade against each other, and vibe coding shoves the entire bill into the future. The feature you generated in twenty minutes might take three engineers two days to safely modify nine months later, because nobody — including the model that wrote it — holds a durable map of how it connects to everything else.
This is the part founders systematically underestimate. The cost of code is dominated by reading and changing it, not writing it. And AI-generated code is often harder to read and change than hand-written code, because it was optimized to run, not to be understood. It works. It just doesn't explain itself.
Picture a realistic scenario. A two-person startup vibe-codes an MVP in six weeks and raises a seed round on the traction. Now they need multi-tenancy, an audit log, and SSO — features that touch nearly every part of the system. They open the codebase and find:
- Authentication logic implemented three different ways in three different modules.
- No single source of truth for the data model; tables were created ad-hoc per feature.
- The business logic the demo depended on spread across route handlers with no clear boundaries.
The model didn't make a mistake anywhere. Each feature, in isolation, was correct. The cost is in the absence of architecture — the connective tissue that lets a system grow. That's exactly the wall teams hit when they try to scale a vibe-coded prototype to production, and it's why the rewrite-from-scratch instinct shows up so reliably at Series A.
The productivity curve actually inverts
The whole promise of vibe coding is productivity, so it's worth being precise about what the research shows. The honest picture is more interesting than the hype.
Google's DORA team, in its State of DevOps work on AI-assisted development, found that AI adoption can increase individual throughput while simultaneously reducing software delivery stability when teams lack the practices to absorb the extra change. More code moves faster through a system that can't validate it as quickly as it's produced. Speed at the keyboard does not automatically become speed at the org level.
That's the inversion in one sentence. Plot productivity against codebase size and the vibe-coding curve looks like this:
| Phase | Codebase size | Vibe-coding productivity | What dominates the cost |
|---|---|---|---|
| Prototype | 0–5k LOC | Very high — near magical | Almost nothing; generation is free |
| Early product | 5k–30k LOC | High, starting to wobble | Re-sending context, first duplicates |
| Scaling | 30k–100k LOC | Declining | Repair loops, clone fixes, slow reviews |
| Production at scale | 100k+ LOC | Often net-negative vs. structured dev | Maintenance tax, fear of changing code |
The danger is that the prototype phase is so good it sets expectations for everything after. Founders extrapolate the early slope and budget headcount, runway, and roadmaps against a productivity rate the workflow can't sustain past a certain size. When the curve bends, it reads as a team problem — "we need to hire senior engineers" — when it's actually a method problem.
Why "just review it harder" doesn't fix it
The obvious response is to review AI output more carefully. It helps at the margin and fails at scale, for a simple reason: human review throughput is roughly fixed, AI generation throughput is not. If the model produces ten times more code, manual review becomes the bottleneck, and the rational team response is to review less carefully to keep shipping. So the very tool meant to speed you up has quietly moved your quality gate from "always" to "when we have time." Real protection comes from validating AI-generated code structurally — against a known architecture, before it merges — not from staring at more diffs.
What changes when AI generates inside an architecture
Every cost above traces back to one root: AI generates code into an environment with no enforced structure. Fix the environment and the costs collapse together, because they were never four problems. They were one problem with four invoices.
This is the bet GitMir is built on. Instead of prompting an agent into an empty file and hoping the output composes, you model the product first as a visual system — modules, data flows, APIs, business logic — and the AI generates structured, editable objects inside that architecture. The architecture isn't documentation written after the fact. It's the container the generation happens in. That single change moves the needle on all four hidden costs:
- Tokens. The model doesn't re-derive your system on every prompt, because the architecture is the durable context. Scoped retrieval and reusable validated components are why the workflow targets roughly 15x fewer LLM tokens than ad-hoc prompting — the savings are mechanical, not a discount.
- Duplication. Because components are first-class, reusable objects, the model reuses what exists instead of cloning it. The duplication curve researchers have measured doesn't apply when reuse is the default path, not the harder one.
- Maintenance. A visual architecture is a map. When you need multi-tenancy nine months later, you can see where auth lives and what touches it, instead of grepping for three implementations.
- Validation. Output is checked against the structure before deploy, which kills the repair loop at its source and keeps the quality gate at "always" instead of "when we have time."
Fair about the landscape: Cursor and Copilot are excellent in-editor accelerators and will stay in your workflow; v0 and Lovable are great for spinning up UI and prototypes fast; Bubble and other no-code tools trade flexibility for speed in a different way; Replit Agent is strong for end-to-end greenfield builds. The distinction isn't "AI good, AI bad." It's where the AI writes. Tools that generate into a freeform file inherit the scaling costs in this article. A system that generates into a validated architecture is designed not to. We put the tradeoffs side by side on the comparison page if you want the specifics.
A concrete before/after
Take the same feature — add role-based permissions to a 60k-LOC app — two ways.
Freeform vibe coding: attach the relevant files (and several irrelevant ones), prompt, get an inline permission check, discover it duplicates an existing guard, prompt again, hit a type error, prompt again, merge it, and create the fourth slightly-different auth path in the system. Four repair rounds, ~150k+ input tokens, one new clone, and a future maintenance debt nobody logged.
Architecture-first: the permission model is an object connected to your existing auth module; the AI generates the check as a reuse of that object; validation confirms it conforms before you see it; zero new clones; near-zero repair rounds; an order of magnitude fewer tokens. Same feature, radically different five-year cost.
How to actually estimate your hidden cost
You can't manage what you won't quantify. So here's a back-of-envelope method any founder can run this week:
- Token reality check. Pull last month's AI API spend and divide by features shipped. Watch that number over three months. If cost-per-feature is rising while features get smaller, you're paying the re-send tax.
- Duplication audit. Run a clone detector (jscpd, PMD CPD, SonarQube) on your repo. Anything above ~10–15% duplicated lines, trending up, is the pattern industry research describes showing up in your own code.
- Change-cost trend. Track median PR cycle time for changes to existing features over six months. If it's climbing while team size is flat, the maintenance tax is live.
- Review-gate honesty. Ask how much AI-generated code merges without a careful human read. If the honest answer is "more than it used to," your quality gate has already slipped.
The hidden cost of vibe coding is only hidden until you measure cost-per-feature, duplication percentage, and change-cycle time. All three are cheap to track and brutally honest.
Run those four numbers and you'll have a defensible estimate of what your current workflow costs beyond the subscription line. What shocks most teams isn't any single number. It's the trend — every metric pointing the wrong way at once, which is the signature of a method problem rather than a people problem.
The takeaway
Vibe coding isn't a mistake. It's the right tool for the first slice of a product and a genuine accelerator inside the editor. The mistake is running an unchanged freeform workflow past the scale where it works, and budgeting against a productivity rate it can't sustain. Ignore the costs and they don't disappear — they move downstream and compound: token bills that grow with your codebase, duplication that erodes quality, a maintenance tax that lands at exactly the moment you're trying to scale, and a productivity curve that quietly inverts.
The fix isn't to stop using AI. It's to give AI a structure to generate inside — so reuse beats duplication, validation beats the repair loop, and your architecture stays legible as it grows.
If you want a number instead of an argument, calculate your ROI to see what your current AI workflow likely costs at your scale, and what an architecture-first approach recovers. Then see how GitMir works — visual architecture, AI generating validated objects inside it, reusable components — and start free in the GitMir IDE to test it against what you just measured.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
Is vibe coding cheaper than traditional development?
Cheaper upfront, often more expensive overall. Vibe coding makes the first draft nearly free but pushes cost downstream into token re-sends, duplicated code, and a maintenance tax that lands as your system grows. At prototype scale it wins; at production scale the total cost of ownership frequently exceeds structured development. Measure cost-per-feature over time, not per session.
Why does my AI coding bill keep going up?
Because token spend scales with codebase size, not request size. Every prompt re-sends files, conventions, and prior context the stateless model can't remember, and repair loops re-send all of it again on each failed generation. As your system grows, agents over-fetch context "to be safe," so a small feature on a large codebase can cost more than a large feature did months earlier.
Does AI-generated code create technical debt?
Yes, primarily through duplication. Industry research found duplicated code blocks rose roughly eightfold in 2024 while refactoring fell sharply, because AI agents bias toward generating fresh code over reusing what exists. That produces clones, inconsistent implementations, and a maintenance burden where one fix must be applied in several places — the classic shape of accumulating technical debt.
At what point does vibe coding stop working?
Roughly when your codebase outgrows the model's context window — often somewhere past 30,000 to 100,000 lines, depending on structure. Below that, the agent can effectively see the whole system; above it, it guesses at interfaces it can't read, re-sends context constantly, and generates code that collides with what already exists. The productivity curve bends from very high toward net-negative.
How do I reduce the hidden costs of AI coding without abandoning AI?
Change where the AI writes, not whether it writes. Generate code inside a controlled architecture so reuse beats duplication, validate output structurally before merge to kill repair loops, and cache stable context so you stop re-sending your whole system every prompt. Together these recover token spend and cap the maintenance tax while keeping AI's speed advantage intact.
How can I measure the real cost of my AI coding workflow?
Track four numbers over three to six months: AI spend divided by features shipped, duplicated-line percentage from a clone detector, median PR cycle time for changes to existing features, and how much AI code merges without careful review. If cost-per-feature and duplication rise while review rigor falls, you're paying the hidden costs this article describes.

Related articles

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.

How to Cut AI/LLM Token Costs in Development (Up to 15×)
AI coding bills scale with tokens, and ad-hoc prompting burns them fast. Here's why token spend explodes — and the pipeline changes that cut it dramatically.

What Is AI-Native Development? A Plain-English Guide
AI-native development means building software where AI is the primary builder and humans direct, review and architect. Here's what changes, what stays, and how to do it without losing control.