
How to Take a Vibe-Coded Prototype to Production
Vibe coding gets you a working prototype fast. Turning it into something you can run, scale and maintain is a different job. Here's the path from demo to durable product.
Taking a vibe-coded prototype to production is mostly subtraction and structure. It's not a rewrite. The prototype already proved the idea works and that people want it — that's the hard part, and AI handed it to you in a weekend. What it didn't hand you is a system: invariants, boundaries, auth that holds, data that stays consistent, and a codebase a second engineer can reason about without a séance. The path to production is the disciplined process of imposing that structure on code an AI improvised without it.
Here's the direct answer to how you do it. First, freeze the prototype and treat it as a spec, not a foundation — it tells you exactly what to build, not necessarily how. Second, extract the real architecture (data model, modules, API surface, business rules) and make it explicit and reviewable. Third, regenerate or refactor the messy parts inside that architecture instead of letting the model keep improvising. Fourth, add the production layer the demo skipped: authentication, authorization, input validation, error handling, observability, and tests on the paths that can lose money or leak data. Fifth, deploy behind a real release process so you can ship daily without holding your breath.
The teams that get burned skip step two. They scale the prototype directly — more features, more prompts, more users — until the thing that was fast to build becomes impossible to change. This article is the founder-to-founder version of how to avoid that: how to take vibe coding from a prototype that demos well to software that survives real users, real money, and real engineers joining the team.
Why "just keep vibe coding" stops working at production scale
Vibe coding wins because AI is an extraordinary pattern completer. Ask for a login form, a CRUD endpoint, a Stripe webhook handler, and the model produces clean, idiomatic code in seconds because it has seen ten million of each. For a prototype, that's pure leverage — you explore five ideas in the time it used to take to scaffold one.
But the model has no memory of your system. It doesn't remember the architectural decision you made three prompts ago, it has no concept of your data invariants, and it has a structural bias toward writing more code to satisfy the literal request. At prototype size — a few thousand lines, one developer, no real users — none of that matters. At production size it's the whole ballgame.
A prototype is a hypothesis with a UI. Production is a promise. The work of taking one to the other is the work of turning improvisation into something you can keep promising.
The failure mode is gradual, which is what makes it dangerous. Each new feature gets prompted against a context the AI only half understands, so it duplicates logic it can't see, invents a second way to do auth, and writes a third date-formatting helper. The codebase doesn't break. It thickens. And velocity quietly inverts: the feature that took an hour in week one takes a day in week ten, because every change now risks something the model can't account for and you can no longer hold in your head. If that's already happening, the signs your AI codebase is becoming unmaintainable are worth a hard look before you add another feature on top.
The fix isn't to stop using AI. It's to stop letting AI improvise the structure, and make it generate code inside a system you control. That distinction is the entire difference between a prototype and a product. (If you're still nailing down terms, here's what vibe coding actually is and where its limits are.)
Step 1: Treat the prototype as a spec, not a foundation
The most expensive mistake at this stage is emotional. You spent a weekend building it, it works, so you defend it as the foundation. Reframe it. The prototype's job was to answer questions — Do people want this? What's the core flow? Where's the magic? — and it answered them. That makes it the best product spec you'll ever have, because it's executable.
Go through the prototype and separate two things:
- What it proves — the user flow, the value, the data the product genuinely needs, the integrations that matter. This is gold. Keep all of it.
- How it's built — the structure the AI happened to produce. This is disposable until proven otherwise. Some of it is fine. Some of it is a load-bearing hack you'll regret.
A concrete example. A founder vibe-codes a scheduling tool. The demo flow is perfect: connect calendar, pick availability, share a link, get booked. Underneath, "availability" is stored as a JSON blob of stringified times in the user's local timezone, double-booking is prevented by a client-side check, and the booking confirmation email is sent from a hardcoded API key in the frontend. The flow is a great spec. The implementation is three production incidents waiting in line. Knowing which is which is the first real engineering decision you make.
Step 2: Extract the architecture the AI never wrote down
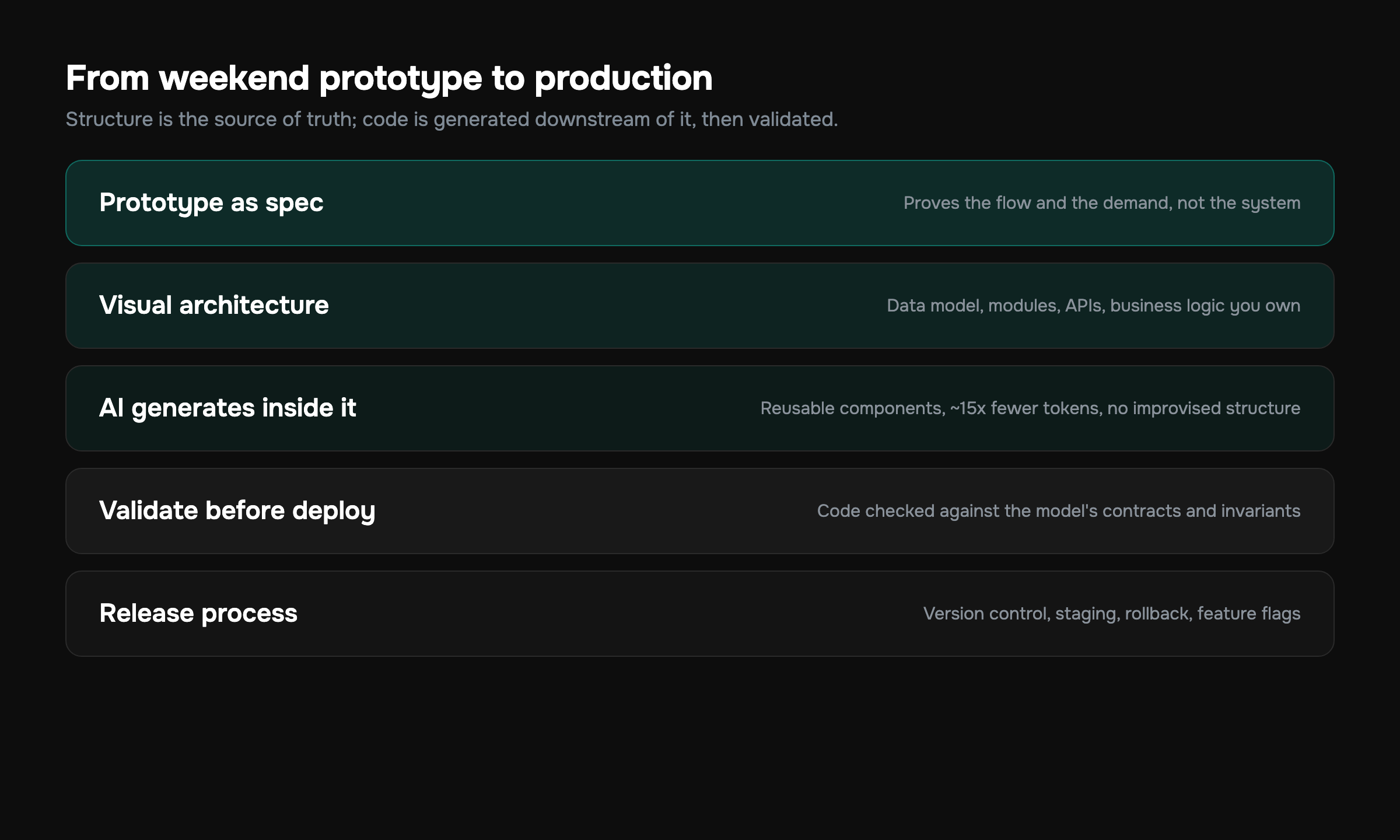
This is the step that separates teams who ship from teams who stall, so it gets the most attention. A vibe-coded prototype has an architecture — it's just implicit, scattered across files, and partly wrong. Your job is to make it explicit, look at it as a whole, and fix it before you build on it.
The architecture you need to surface and own:
- Data model — entities, relationships, and the invariants that must always hold (a booking can't exist without a user; an order total must equal the sum of its line items). The AI almost certainly got some of these wrong, because it was reasoning one prompt at a time.
- Module boundaries — what the distinct parts of the system are (auth, billing, scheduling, notifications) and what each is allowed to touch. Prototypes have none of this; everything reaches into everything.
- API surface — the contracts between frontend and backend, and between your system and third parties. These need to be stable, validated, and versioned, not implicit.
- Business logic — the rules that are actually your product (pricing, permissions, eligibility). In a prototype these are usually smeared across UI handlers. They belong in one reasoned place.
- Data flows — how a request moves through the system and where state changes. This is what a new engineer needs to understand on day one and what the AI can never see.
Make the architecture visible, not tribal
The reason this is hard with conventional tools is that the architecture lives in the heads of whoever wrote it. And with vibe coding, nobody wrote it; the model emitted it. So there's no head to ask. You're reverse-engineering intent from code that had no intent.
This is exactly the gap GitMir is built to close. Instead of architecture being an invisible property you reconstruct by reading files, you model the product visually — modules, data flows, APIs, and business logic become structured objects you can see, review, and reason about as a system. AI then generates code inside that architecture rather than improvising a new one each prompt. The structure is the source of truth; the code is downstream of it. If you'd rather extract what you have first, you can document your existing software architecture automatically and start from a real map instead of a guess.
You can't refactor what you can't see. Most "the AI made a mess" problems are really "the architecture was never visible, so nobody could tell good code from a time bomb."
The comparison that matters here:
| Approach | Where architecture lives | What AI generates | What you review |
|---|---|---|---|
| Pure vibe coding (Cursor, Copilot, Lovable, v0) | Implicit, in the code | Free-form code per prompt | Diffs, file by file |
| No-code (Bubble) | In the platform's model, but locked to it | Nothing — you assemble | Visual config, not real code |
| Visual architecture (GitMir) | Explicit, modeled, owned by you | Structured, editable objects inside the architecture | The architecture and the code, as a system |
Cursor and Copilot are excellent at the line; they make a fast engineer faster. Lovable, v0, and Replit Agent are excellent at the zero-to-demo leap. None of them were designed to hold a whole system accountable. That's not a knock — it's a scope difference, and it's precisely the scope production demands. (For a head-to-head on where each fits, see the tool comparison.)
Step 3: Regenerate the messy parts inside a controlled system
Once the architecture is explicit, the rewrite stops being scary. You're not rebuilding the product. You're regenerating individual modules against a contract you defined. This is where AI flips from liability back to leverage, because now it's filling in well-bounded blanks instead of inventing structure.
A pragmatic order of operations:
- Data model first. Get the schema, constraints, and invariants right, because everything else sits on top. Fix the JSON-blob-of-stringified-times before you touch anything else.
- Then the boundaries. Pull billing, auth, and notifications into real modules with clear interfaces. The AI can do most of this mechanically once you've told it what the modules are.
- Then business logic. Centralize the rules that are your actual product. Make them testable in isolation.
- UI last. It's the most disposable and the easiest to regenerate, because by now it's just rendering a clean contract.
The token economics matter more than people expect. Re-prompt a model with no shared structure and you re-send context every time, and it re-derives decisions it should already know — wasted tokens and wasted consistency. Generating inside a defined architecture means the structure is given, not re-explained, which is how GitMir reports up to ~15x fewer LLM tokens than ad-hoc prompting for equivalent work. Cheaper is nice. Consistent is the real prize. You can sanity-check what that does to your own numbers with the ROI calculator.
Reusable components instead of the fourth date helper
A defining symptom of prototype-grade AI code is duplication: the model can't see what already exists, so it rebuilds it. Production code goes the other way — one validated component, reused everywhere. When components are reusable objects in a modeled system rather than copies scattered across files, fixing a bug once fixes it everywhere, and a new feature composes existing parts instead of spawning near-duplicates. This single shift kills most of the "thickening" that strangles vibe-coded codebases over time.
Step 4: Add the production layer the demo skipped
Demos are allowed to skip the unglamorous 60% of software. Production isn't. This is the checklist that turns a working prototype into something you can point real users at without flinching:
- Authentication and authorization. Not just "is the user logged in" but "is this user allowed to do this to this record." Vibe-coded prototypes routinely check the first and skip the second — the classic broken-access-control hole.
- Input validation everywhere. Every boundary where data enters — forms, APIs, webhooks — validated and typed. The AI tends to trust its inputs because the happy path is all it was prompted about.
- Error handling and graceful degradation. What happens when Stripe is down, the DB times out, the third-party API returns garbage. Prototypes assume sunshine.
- Observability. Logs, metrics, and traces so that when something breaks at 2 a.m. you can find it in minutes, not hours.
- Tests on the money-and-data paths. You don't need 100% coverage. You need real coverage on the flows where a bug loses money, corrupts data, or leaks information.
- Secrets and config. No hardcoded keys, no credentials in the frontend, environment-specific config done properly.
The gap between "it works in the demo" and "it works for ten thousand strangers trying things you never imagined" is not a feature. It's a discipline. Production is the demo plus everything that protects you from the user you didn't anticipate.
There's a quieter risk threaded through all of this: validating that the AI-generated code is actually correct, not just plausible. Plausible and correct are different words, and the model optimizes for the first. Validating before deploy — checking generated code against the architecture's contracts and invariants rather than eyeballing diffs — is a core part of the GitMir model and the cheapest insurance you'll buy. For the broader playbook, here's how to validate AI-generated code without becoming a full-time code reviewer.
What the research says about scaling AI-built code
This isn't a vibes-based concern. The data backs it up. According to Google's DORA research program, the largest and longest-running study of software delivery performance, its 2024 Accelerate State of DevOps findings showed that while AI adoption boosted individual productivity, a roughly 25% increase in AI usage was associated with a measurable decrease in software delivery stability — meaning more changes failing in production and slower recovery. AI made writing code faster. It did not, on its own, make shipping it safer.
The lesson isn't "AI is bad." It's that raw generation speed and delivery stability are different metrics, and the gap between them is exactly the architectural discipline this article is about. Teams that pair AI speed with explicit structure, validation, and a real release process capture the productivity without inheriting the instability. Teams that scale the prototype directly get the speed and the instability — and the second one compounds. The DORA data is essentially a measurement of step two being skipped at scale.
Step 5: Ship behind a real release process
Once the system is structured and the production layer is in, the last mile is being able to deploy continuously without drama. This is less about heroics and more about boring repeatability:
- Version control with reviewable changes. Every change visible and revertible. If your prototype lived in a single ever-mutating file, this is the moment to fix that.
- A staging environment. A place that looks like production where changes prove themselves before users see them.
- Automated deploys with a rollback. One command to ship, one command to undo. The rollback is the part that lets you ship boldly.
- Feature flags for risky changes. Ship the code dark, turn it on for 5% of users, watch, then expand. This is how you de-risk the changes the AI is most likely to get subtly wrong.
- A simple incident habit. When something breaks — and it will — you have logs to find it, a rollback to stop the bleeding, and a five-minute note on what to fix so it doesn't recur.
None of this is exotic. It's the difference between "we can ship a fix in ten minutes" and "we're scared to touch it," and that difference is what lets a small team move fast safely once real users are involved.
A realistic timeline: weekend prototype to production
To make it concrete, here's how this actually sequences for a typical SaaS prototype built by one or two founders. The point isn't the exact days. It's the order and the proportions.
- Days 1-2 — Freeze and map. Stop adding features. Extract the implicit architecture: data model, modules, API surface, business rules. Mark every load-bearing hack. (Steps 1-2.)
- Days 3-7 — Fix the foundation. Correct the data model and invariants first, then carve out real module boundaries. Regenerate the worst offenders inside the new structure. (Step 3.)
- Week 2 — Production layer. Auth/authz, validation, error handling, observability, tests on the money paths, secrets cleanup. (Step 4.)
- Week 2-3 — Release process. Version control hygiene, staging, automated deploy + rollback, feature flags. Then ship to real users. (Step 5.)
The two-to-three week shape is realistic if the architecture extraction in step two is done honestly. Skip it, and the timeline doesn't shrink — it just moves the cost downstream, where it's three times more expensive and arrives as an outage instead of a refactor.
Where the platform choice changes the math
The above assumes you're doing the structural work by hand on top of code an AI improvised. GitMir exists to collapse steps two and three: because the architecture is modeled visually and the AI generates inside it, you're not reverse-engineering intent from a pile of diffs — the structure is already explicit, the components are already reusable, and validation happens against the model before deploy rather than in production. It doesn't remove the production layer in step four (nothing does), but it removes the single most error-prone and time-consuming part: turning implicit, AI-improvised structure into something you can actually build on. You can see how that works on the product page.
The mindset shift that makes all of this click
If there's one thing to internalize, it's this. The prototype and the production system are not the same artifact at different stages of polish. They're two different things that happen to look alike. The prototype's value is information — proof the idea works. The production system's value is structure that protects that idea under load. Vibe coding is unbeatable at producing the first. It is, by design, indifferent to the second.
So the move isn't to abandon vibe coding when you go to production. It's to keep the speed and add the spine. Let AI generate, but generate inside an architecture you can see, validate, and own. Reuse components instead of regenerating them. Validate before deploy instead of debugging in front of users. Do that, and you keep the weekend-prototype velocity all the way through scale, instead of watching it invert the moment the codebase grows past what one person can hold in their head.
Speed without structure is a loan. The interest comes due exactly when you can least afford it — when real users show up. Structure is how you take the speed and skip the interest.
Your next step
Got a prototype that's working and you're staring down the "okay, now make it real" wall? Start by getting honest about your architecture. Map what you actually have before you build another thing on top of it — and if you're feeling the codebase thicken, read the signs your AI codebase is becoming unmaintainable first.
Then run the numbers on what doing this with a controlled, visual architecture saves versus continuing to prompt your way forward: the ROI calculator shows the token and time difference for your own situation, and the product page shows what generating code inside an architecture you can see actually looks like. If you're still deciding what to build with, the tool comparison page lays out where GitMir fits next to Cursor, Copilot, Lovable, v0, Replit Agent, and Bubble — and the GitMir IDE is free to start. The prototype proved the idea. Now give it a spine.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
Can you take a vibe-coded prototype to production without rewriting everything?
Usually yes — most of the prototype's value (the flows, the data it needs, the integrations) is reusable as a spec. You rarely rewrite the whole thing. Instead you extract the real architecture, fix the data model and boundaries, regenerate only the messy modules inside that structure, and add the production layer the demo skipped.
What's the biggest risk when scaling a vibe-coded prototype?
Scaling the implicit architecture instead of fixing it first. Because AI improvised the structure one prompt at a time, it duplicates logic, invents multiple ways to do auth, and bakes in invariant bugs. Add features on top and the codebase thickens until it's impossible to change safely — velocity inverts and small changes start causing outages.
Is vibe coding safe for production software?
Vibe coding is safe for production only when AI generates code inside an architecture you control, with validation before deploy. Pure vibe coding — accepting code you don't review against a structure — is excellent for prototypes and dangerous for anything handling real users or money. The fix is structure and validation, not abandoning AI-assisted speed.
How long does it take to move a prototype to production?
For a typical one-or-two-founder SaaS, plan two to three weeks: a couple of days to freeze and map the architecture, several days to fix the data model and module boundaries, about a week for the production layer (auth, validation, observability, tests), and a few days to set up a real release process before shipping to users.
What does a vibe-coded prototype usually get wrong technically?
Most commonly: a sloppy data model with broken invariants, authorization checks that confirm login but not permission, hardcoded secrets (sometimes in the frontend), no input validation past the happy path, duplicated logic the AI couldn't see, and zero error handling for when dependencies fail. Demos hide all of this; real users find it fast.
How is GitMir different from Cursor, Lovable, or Bubble for going to production?
GitMir makes architecture explicit and visual — modules, data flows, APIs, and business logic are objects you own, and AI generates structured code inside them, validated before deploy. Cursor and Copilot speed up the line; Lovable and v0 nail the demo; Bubble locks you into its model. GitMir is built for holding a whole system accountable at production scale.

Related articles

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.

What Is AI-Native Development? A Plain-English Guide
AI-native development means building software where AI is the primary builder and humans direct, review and architect. Here's what changes, what stays, and how to do it without losing control.

7 Signs Your AI Codebase Is Becoming Unmaintainable
AI-built codebases can rot quietly until a small change takes a week. Here are seven early warning signs — and what to do before it's a rewrite.