
How to Document Software Architecture (Almost) Automatically
Architecture docs go stale the moment they're written. The fix isn't more discipline — it's making the architecture itself the living source of truth. Here's how.
Your architecture documentation is always out of date because you treat it as a deliverable instead of a byproduct. Someone draws a diagram for a design review. It's accurate for about a week. Then the code drifts, and six months later that diagram is a lie nobody trusts and nobody updates. The fix isn't more discipline or another documentation sprint every quarter. To document software architecture so it stays current, make the architecture the thing you build from — then documenting it stops being a separate act and becomes just reading the source of truth.
Here's the short answer. You document software architecture almost automatically by inverting the relationship between the model and the code. Instead of writing code and then describing it, you keep a structured, machine-readable model of the system — modules, data flows, APIs, contracts, business rules — and treat that model as the artifact the code is generated and validated against. When the model is the system, the documentation is generated, not written. The diagram is a render of the real structure. The API reference is the actual contracts. The dependency map is the actual edges. It can't go stale, because if it drifted from reality the build would break.
The "almost" matters, and I'll keep it honest throughout. No tool writes the why for you — the trade-offs, the rejected alternatives, the business reason a boundary sits where it does. That's the 20% you'll always author by hand. But the 80% that consumes most of your documentation effort and rots the fastest — the structural map of what exists and how it connects — can and should be generated. This article is about how to get there: what to automate, what to never automate, and where AI development tools help versus where they quietly make the problem worse.
Why architecture documentation rots (and why it's getting worse)
Every team has lived this. The architecture diagram on the wiki shows a clean three-service system. The real system has eleven services, two of them undocumented, one of them a "temporary" Lambda from 2024 that now handles all your webhooks. Nobody lied. The diagram was true once. It just had no mechanism to stay true.
That's the core problem with how to document software architecture the traditional way: documentation and code are two separate artifacts that you manually keep in sync, and manual sync against a moving target always loses. The code changes every day. The diagram changes when someone remembers, which is never.
Three forces make this worse in 2026 than it was even two years ago:
- AI-accelerated output. Teams shipping with Cursor, Copilot, and agentic tools generate code far faster than any human updates a diagram. The gap between what exists and what's documented widens every sprint.
- More surface area, less authorship. When a human writes every line, they at least carry a partial mental model of the system. When an agent generates a module in thirty seconds, nobody fully holds it in their head — so there's no internal model to even export into a doc.
- Higher churn. AI makes rewriting cheap, so structure shifts more often. Documentation that assumed a stable system can't keep up with one that mutates weekly.
Architecture documentation has a half-life. The day you draw it, it's 100% accurate. Every commit after that, it decays. The only way to beat decay is to stop drawing documentation and start generating it from the same artifact you build from.
The hidden cost isn't writing it — it's trusting it
The expensive failure mode isn't the hours spent writing docs. It's the moment a senior engineer says "don't trust the wiki, ask me" — and now the documentation has negative value, because it actively misleads while still looking authoritative. A wrong architecture diagram is worse than no diagram. No diagram makes people ask questions; a wrong one makes them confidently build on a foundation that isn't there. This is the same dynamic that makes onboarding new engineers so slow — the map they're handed describes a city that's been rebuilt twice since.
What "architecture documentation" actually has to capture
Before automating anything, get precise about what you're documenting. "Architecture documentation" is a vague phrase that bundles five very different artifacts, and they automate at very different rates.
| Layer | What it captures | Can it be generated? |
|---|---|---|
| Topology | Modules, services, data stores, and how they connect | Yes — fully, from the model |
| Data flows | What happens when a user does X; which components fire, in what order | Yes — if flows are modeled, not implied |
| Contracts | API signatures, schemas, events, invariants at each seam | Yes — these are the source of truth |
| Conventions | Naming, error handling, where business logic is allowed to live | Partly — enforceable rules generate, taste does not |
| Rationale (the "why") | Trade-offs, rejected alternatives, business context | No — human authorship, always |
The strategic insight is in the last column. The first three layers — topology, data flows, contracts — are roughly 80% of the documentation effort and 100% of the rot. They're also entirely derivable from a structured model of the system. The "why" is the irreducible human part, and it's small. So the goal of automatic architecture documentation isn't to replace the architect. It's to delete the 80% of busywork that was never a good use of an architect's time, so the human attention goes where only humans can go.
The core move: make the model the source of truth
There are two ways to relate a model to code, and they produce completely opposite outcomes for documentation.
Code-first (the default). You write code. The architecture is an emergent property of that code — it exists, but only implicitly, scattered across files. To document it, you reverse-engineer the structure back out, by hand or with a tool, into a diagram that immediately starts drifting. Documentation is downstream of code and always trailing it.
Model-first (the inversion). You define the structure explicitly — modules, boundaries, flows, contracts — as a first-class artifact. Code is generated and validated against that model. Documentation isn't reverse-engineered; it's a direct rendering of the model you already authored. The documentation is the same artifact as the system.
The model-first inversion is the entire game. Once the model is the source of truth, "documenting the architecture" collapses into "rendering the model," which is free and always current. This is exactly the principle behind building software with AI you can actually see: the visual model isn't a picture of the system, it is the system, and the picture is just the view.
The question "is our documentation up to date?" only makes sense when documentation is separate from the system. Make them the same artifact and the question dissolves. You can no longer have stale docs for the same reason you can't have a stale checkout of main — there's only one thing.
Where this lives on the spectrum
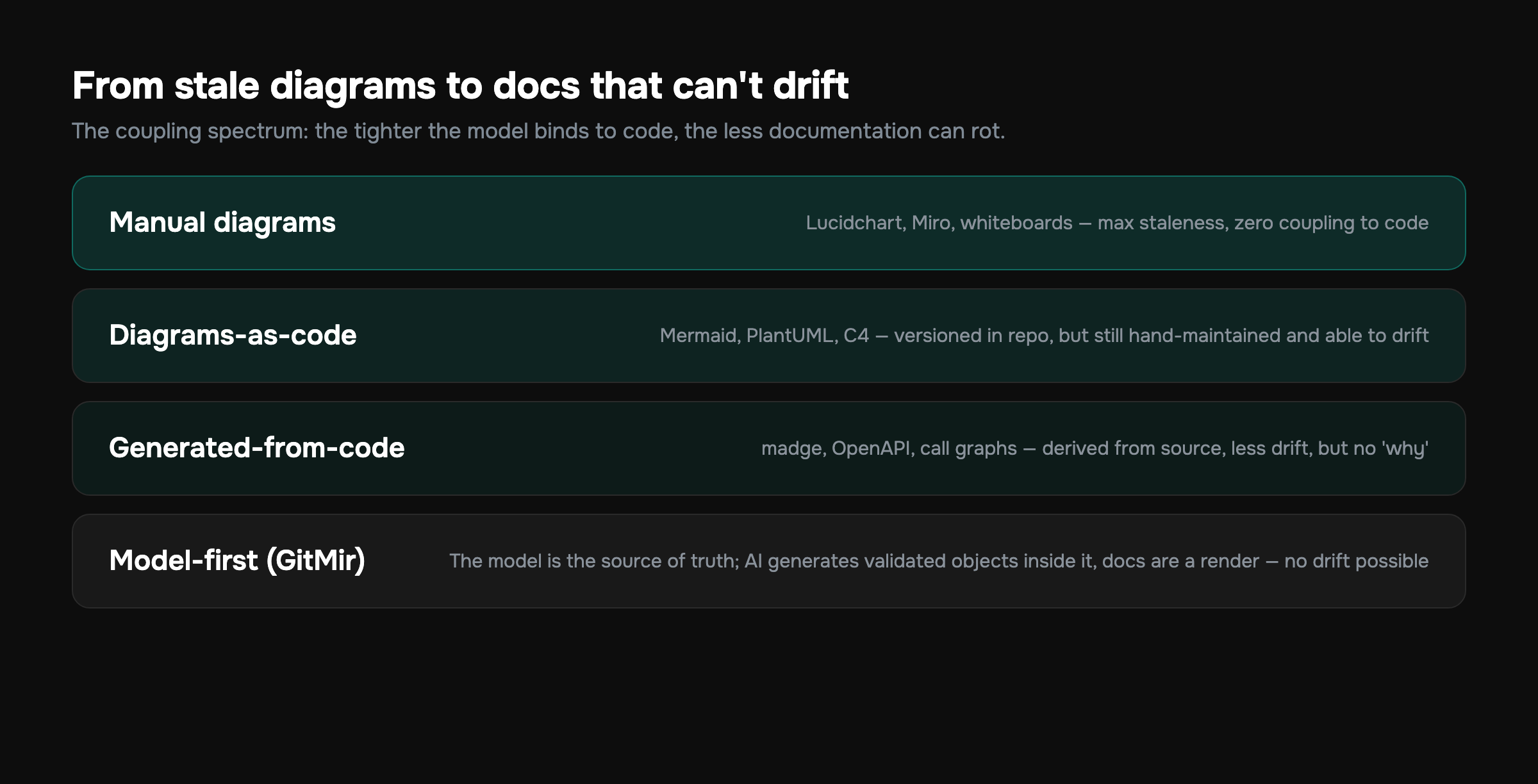
You don't have to go all the way to model-first to benefit. There's a spectrum:
- Manual diagrams (Lucidchart, Miro, whiteboard photos) — maximum staleness, zero coupling to code.
- Diagrams-as-code (Mermaid, PlantUML, Structurizr/C4) — text in the repo, version-controlled, but still hand-maintained and able to drift from the real code.
- Generated-from-code (dependency graphs, OpenAPI from annotations, call-graph extractors) — derived from the source, so less drift, but only captures what the extractor can infer, and "why" is lost entirely.
- Model-first (the system is generated from the model) — the model is authoritative, code conforms to it, documentation is a render. No drift is possible by construction.
Most teams are stuck at level 1 or 2 and feel the pain. Level 3 is a real improvement and worth doing today with tools you already have. Level 4 is where documentation becomes genuinely, structurally automatic — and it's where platforms built around visual architecture aim.
A practical playbook you can start this week
You don't need a platform migration to get most of the value. Here's a concrete progression, ordered by leverage.
1. Generate your contracts, don't write them
Your API documentation should never be hand-written prose. Generate an OpenAPI/Swagger spec from your actual route definitions and types. Generate your GraphQL schema docs from the schema. Generate event-contract docs from your message schemas. When a contract changes, the generated doc changes, and any consumer reading stale docs breaks loudly instead of silently. This single move kills the most dangerous category of stale documentation — the kind that lies about an interface.
2. Generate your dependency and module map in CI
Add a step to your pipeline that extracts the real module/dependency graph on every merge and publishes it. Tools exist for every major ecosystem (madge, dependency-cruiser, arch-unit-style checks, language servers). The map is regenerated on every commit, so it's never more than one merge stale. And there's a bonus: you can fail the build on forbidden edges — "the billing module must not import the auth internals" — which turns your architecture diagram into an enforced contract rather than a wish.
3. Capture flows as the come into existence, not after
Topology is easy to extract. Flows are the hard part, because "what happens when a user checks out" is a runtime story that's only implicit in the code. The trick is to make flows explicit artifacts at design time — a sequence the system is built to follow — rather than reconstructing them later from logs and tracing. On a model-first platform, flows are something you draw and the system honors. If you're code-first, distributed tracing (OpenTelemetry) is your best approximation: it documents the flows that actually ran.
4. Author only the "why," and keep it next to the boundary
For the irreducible human 20%, adopt lightweight Architecture Decision Records (ADRs): one short markdown file per significant decision, capturing context, the choice, and the rejected alternatives. Keep them in the repo next to the code they govern. ADRs age gracefully because they're explicitly historical — an ADR from 2024 is supposed to describe 2024's reasoning. You're not maintaining them. You're appending to a log.
5. Wire the generated artifacts into one view
Generated contracts, a CI-built module map, modeled flows, and ADRs are four streams. The win is composing them into a single navigable view a new engineer or a returning author can open and trust. When that view is generated, "update the docs" is no longer a ticket anyone has to remember.
Where AI development tools help — and where they hurt
This is where teams get it backwards. The instinct is "AI is great at writing, so let's have AI write our architecture docs." That's a trap. Point an LLM at a repo and ask for a description and you get a confident, plausible, unverifiable summary that's stale the moment the next commit lands. You've automated the production of stale docs, not eliminated staleness.
The useful question isn't "can AI write the docs?" It's "can AI generate code in a form that's self-documenting by construction?" Those are very different bets.
The two ways to use AI on this problem
Ad-hoc prompting (Cursor, Copilot, v0, Lovable, Replit Agent). You describe what you want, the AI emits code into files. This is genuinely fast for producing code. But the architecture is still emergent and implicit — the AI scattered logic across files the same way a human would, except now no human even holds the mental model, because no human wrote it. Documentation is still a reverse-engineering problem, and now it's harder, because there's no author to ask. These tools accelerate the very output that outpaces your documentation.
Generation inside a controlled model (the architecture-first approach). The AI doesn't emit free-form files. It generates structured, editable objects inside an architecture you've modeled — placed in the right module, conforming to the defined contracts, validated against the rules before anything deploys. Because the output lands in the model, the documentation is a render of the model, automatically. The AI made the system bigger without making it less legible.
This is the design principle behind GitMir: you model the product and build the visual architecture — modules, data flows, APIs, business logic — and AI generates structured objects within that architecture, validated before deploy, with reusable components instead of regenerated boilerplate. Because the work happens inside a controlled, scoped model rather than against the whole codebase as raw text, it uses up to roughly 15x fewer LLM tokens than ad-hoc prompting. And, relevant here, the architecture documentation is never a separate task, because the model you built is the documentation.
The difference is subtle but total. Ad-hoc AI coding asks "what code should I write?" and leaves you to document the answer later. Architecture-first AI asks "where in the model does this belong, and what contract must it honor?" — and the documentation is the model you answered inside of.
For a deeper treatment of how this changes the engineering leadership calculus, see our piece on AI development for CTOs.
What the research says about the cost you're actually carrying
It's easy to treat documentation drift as a soft, annoying problem. The data says it's a hard, expensive one — and that AI is amplifying the underlying churn that drives it.
According to Google's DORA "State of DevOps" research, the adoption of AI in software development is reshaping how teams ship — accelerating the rate at which code is produced and changed, while the practices that keep systems legible struggle to keep pace. Faster output cuts the same way for documentation: more change means structure shifts more often, and a system that mutates weekly leaves more distinct things to keep documented. The architecture is moving faster exactly as the human capacity to track it by hand stays flat.
That maps onto what developers say they feel. Industry research finds that a large majority of professional developers now use or plan to use AI tools in their workflow, even as a striking share report low trust in the accuracy of AI output. Read those two findings together and you get the precise shape of the documentation problem. AI is producing more of the code, and humans trust it least, which means the demand for a trustworthy, current picture of what the system actually is has never been higher — at exactly the moment hand-maintained documentation is least able to deliver it. The answer isn't to document harder. It's to make the trustworthy picture a generated byproduct of the system instead of a separate, decaying artifact.
A realistic before/after
Make it concrete. Two teams, same product — a B2B billing platform — building the same new feature: usage-based metering.
Team A — code-first with ad-hoc AI. They prompt Cursor for the metering service, it generates files, they wire it in. It ships in three days. The architecture diagram on the wiki doesn't mention metering, because nobody updated it. Two months later a new hire adds a discount feature, doesn't realize metering already emits the events they need, and builds a duplicate event pipeline. The duplication surfaces six weeks after that as a billing discrepancy in production. Total cost of the stale doc: one duplicated subsystem and one customer-facing incident.
Team B — model-first. They open the visual model, add a metering module, draw its data flow into the existing billing pipeline, define its contracts, and let AI generate the structured implementation inside that boundary — validated against the existing contracts before deploy. It also ships in about three days. But the architecture documentation now includes metering automatically, because the model is the documentation. When the new hire adds discounts two months later, they open the same model, see the metering events already exist, and consume them. No duplicate. No incident. The difference wasn't talent or speed. It was that one team's documentation maintained itself and the other team's didn't.
The gap between these two outcomes is the entire argument for automatic architecture documentation. It's not about prettier diagrams. It's about whether the next person — human or AI — builds on truth or on a six-month-old fiction.
What you should never automate
To keep this honest, here's the boundary. Automating the wrong things creates a false sense of safety, which is worse than knowing you have a gap.
- Don't auto-generate rationale. An LLM will happily write a plausible "why we chose Kafka" paragraph. It's fabrication. The why must come from the humans who made the decision, captured in an ADR at decision time.
- Don't trust LLM prose summaries of a repo as documentation of record. They're useful for a quick orientation, dangerous as a source of truth, because they're unverifiable and instantly stale.
- Don't automate away the review of generated structure. Generation inside a model is powerful, but a human still owns whether the boundary is right. Validation checks that code conforms to the model; it can't tell you the model itself is well-designed.
- Don't let "it's generated" mean "nobody looks at it." The point of automatic documentation is to free human attention for design, not to eliminate human attention from the system.
Bringing it together
Documenting software architecture almost automatically comes down to one decision made early and held: the architecture is a first-class, structured model, and everything else — the code, the diagrams, the API reference, the dependency map — is generated from or validated against it. Get that relationship right and documentation stops being a chore you lose at and becomes a property you get for free.
The practical path is incremental. Generate your contracts today. Build your module map in CI this sprint. Capture flows as explicit artifacts instead of reconstructing them from logs. Author only the why, in ADRs, next to the code. And when you're deciding how AI fits, choose the version where AI generates inside a controlled architecture — so it makes the system bigger without making it less legible — rather than the version where it floods your repo with code no document can keep up with.
Your next step
If your team is shipping fast with AI and your architecture documentation can't keep up, the lever isn't a documentation sprint. It's changing where the source of truth lives.
Put a number on what drift is costing you: run your team size, change volume, and AI spend through the ROI calculator to see what stale architecture and ad-hoc token waste actually add up to. If you'd rather see the model-first workflow directly — visual architecture, AI generating validated objects inside it, documentation as a render — look at the product. And when you're weighing it against the tools already in your stack, the comparison page draws the lines clearly, and the GitMir IDE is free to start. The best architecture documentation is the kind you never have to write, because the system you built is already the document.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
Can you really document software architecture automatically?
Mostly, yes. The structural parts — topology, data flows, API contracts, and the dependency map — can be generated directly from a machine-readable model of the system, so they never drift. The one part you can't automate is rationale: the trade-offs and business reasons behind a decision. That irreducible 20% you author by hand, typically as short Architecture Decision Records kept beside the code.
Why does architecture documentation always go out of date?
Because documentation and code are usually two separate artifacts that you manually keep in sync, and manual sync against a daily-changing codebase always loses. The diagram is accurate the day it's drawn and decays with every commit after. The durable fix is to make the documentation a render of the same model you build from, so it physically cannot drift apart from the running system.
What's the best way to keep architecture diagrams in sync with code?
Generate them from the source of truth instead of drawing them alongside it. Build your module and dependency map in CI on every merge, generate API references from your actual route and schema definitions, and fail the build on forbidden dependencies. Better still, adopt a model-first approach where the architecture model is authoritative and code conforms to it, making the diagram a live view rather than a separate file.
Should I use AI like Cursor or Copilot to write my architecture docs?
No, not to write prose summaries — those are confident, unverifiable, and stale the moment the next commit lands. The useful application of AI is different: have it generate code inside a controlled architecture model, so the output is self-documenting by construction. Tools like GitMir take that approach, placing AI-generated objects inside a validated model so the documentation is a byproduct, not a task.
What is the difference between model-first and code-first documentation?
In code-first, architecture is an emergent property of the code, so documenting it means reverse-engineering structure that immediately starts drifting. In model-first, you define the structure explicitly as a first-class artifact and generate or validate code against it, so documentation is a direct render of the authoritative model. Model-first makes staleness structurally impossible; code-first makes it nearly inevitable.
How do Architecture Decision Records fit into automatic documentation?
ADRs cover the one layer you should never automate — the rationale behind a decision. Each is a short markdown file capturing context, the choice made, and rejected alternatives, kept in the repo next to the relevant code. They age gracefully because they're explicitly historical: you append new ones rather than maintaining old ones, so they complement generated structural docs without rotting.

Related articles

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.

The Laptop Did Not Just Change. The AI Development Model Changed.
NVIDIA's Spark and the AI PC signal a shift: AI agents are moving onto the machine — always-on, local, next to your code. Why that makes architectural visibility non-negotiable.

What Is Vibe Coding? (And How to Do It Without Breaking Production)
Vibe coding means building software by prompting AI instead of writing code by hand. It's fast — but without structure it ships bugs, lost context and hidden architecture. Here's how to keep the speed and the control.