
How to Onboard Engineers Faster With Visual Architecture
New engineers spend weeks just figuring out how the system fits together. Visual architecture cuts that to days. Here's why onboarding is slow and how to fix it.
A new engineer's first month is the most expensive, lowest-output stretch of their entire tenure, and almost none of that cost is coding. It's comprehension. They can write a function on day one. What they can't do is know where that function goes, what it's allowed to touch, which of the four "user" objects is the real one, and whether the pattern they just copied is the blessed one or the deprecated one someone forgot to delete. The fastest way to onboard engineers faster is to stop making them reconstruct your system from scratch in their heads, and start handing them a system they can see.
That's the whole game. Onboarding speed has very little to do with better docs, a friendlier buddy, or a thicker wiki nobody reads. It comes down to how quickly a new hire can build an accurate mental model of your architecture — the modules, the data flows, the boundaries, the contracts — and how confidently they can change something without breaking what they can't see. When that model lives only in senior engineers' heads and a scattered chat history of AI prompts, every new engineer has to rebuild it by interrogating people and grepping code. Make the architecture explicit, visual, and navigable, and the new hire absorbs the system instead of excavating it.
This matters more in 2026 than it did three years ago, and the reason is uncomfortable. AI-assisted coding has made codebases grow faster than anyone's mental map of them. Cursor, Copilot, and agentic tools let a small team produce an enormous surface area of code, much of it generated in one-off prompts with no memory of the decisions made twenty prompts earlier. Your codebase is bigger, messier, and less self-explanatory than it would have been if humans had typed every line deliberately. Onboarding a new engineer into that is brutal — unless the architecture is modeled visually and the AI was made to build inside it. This is a CTO problem now, not a documentation chore. It's the difference between a team that scales linearly and one that scales like a swamp.
Why onboarding is really an architecture problem
Ask a struggling new hire what's blocking them and you'll rarely hear "I don't know the syntax." You'll hear versions of "I don't understand how this fits together." That's the tell. Onboarding friction is almost never about language fluency or tooling setup — those are solved in a day. It's the mental model gap: the distance between what the codebase is and what the new engineer can currently picture.
Every system has an architecture whether you drew it or not. The only question is whether that architecture is legible. In most teams it isn't. It's implicit, distributed across the tenured engineers' intuition, a few stale Confluence pages, a README that lies, and the running code itself — the only artifact that's actually true and the hardest to read. A new engineer's ramp time is essentially the time it takes to reverse-engineer the implicit architecture into an explicit one in their own head, one painful question at a time.
The cruel part: the people who can answer the new hire's questions are your most expensive engineers, and every answer they give is a tax on the work they're not doing. Slow onboarding isn't one cost. It's two — the new hire's lost output and the senior's interrupted flow, compounding for weeks.
So when you say "I want to onboard engineers faster," what you actually want is to compress the mental-model-building phase. There are exactly two levers for that. You can make the system smaller and cleaner — good luck, it only grows. Or you can make the architecture visible so the model is handed over instead of excavated. This article is mostly about the second lever, because it's the one you control, and because AI development has made it the decisive one.
The hidden second tax: re-onboarding the AI
Here's the part most leaders miss. In an AI-native team, you're not just onboarding humans. You're re-onboarding the model on every single prompt. A code assistant with no durable picture of your architecture re-derives it from scratch each time — burning tokens, guessing at boundaries, and producing the inconsistencies the next human will have to untangle. The same missing artifact that slows your new hire slows your AI. Fix it once and both problems shrink together. We'll come back to the token math, because it's startling.
What "ramp time" actually costs (do the math once)
Vague pain doesn't get budget. Let's put numbers on it so the decision is rational.
Take a mid-level engineer at a fully-loaded cost of roughly $180k/year, or about $90/hour. Industry norms — and your own retros — put real productivity ramp somewhere between two and six months depending on system complexity. Call it a conservative eight weeks to ~80% productivity. During those eight weeks:
- The new hire operates at, say, 30% effective output ramping to 80%. The lost productivity alone is on the order of $15k–$25k.
- They consume senior engineers' time — call it 4 hours/week of direct Q&A and review across the team. Eight weeks at senior rates is another $5k–$8k of interrupted expensive labor (the real cost is higher once you price the context-switching, but keep it conservative).
- The whole team's velocity dips because review queues lengthen and the new code lands in places no one quite trusts yet.
So one mid-level hire onto a poorly-documented, AI-bloated codebase is comfortably a $25k–$35k onboarding event, most of it pure comprehension overhead. Hire four engineers in a year and you've spent six figures teaching people what your system is — repeatedly, from scratch, by hand. Cut ramp time from eight weeks to four and you've recovered most of that per hire. That's the prize, and it's why this is a leadership conversation, not a wiki cleanup. (If you want to model this against AI tooling costs too, the ROI calculator is built for exactly this.)
Visual architecture: handing over the map instead of the territory
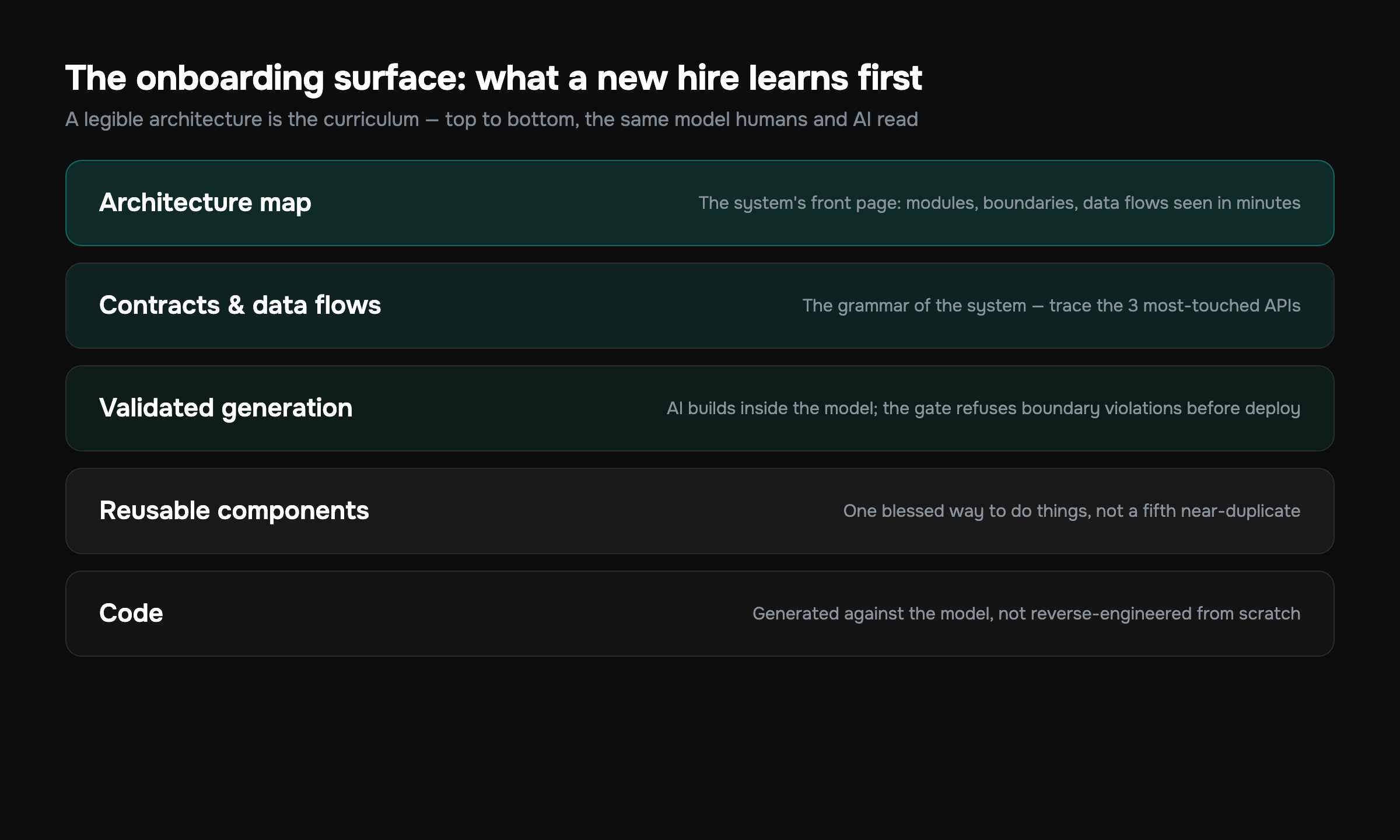
The core move is simple to state and hard to fake. Make the architecture an explicit, visual object that the new engineer can navigate, and that the code is actually built against. Not a diagram someone drew once. A living model of modules, data flows, APIs, and business logic that is the system's design, kept true because the code is generated and validated inside it.
When the architecture is visual and authoritative, onboarding changes shape:
- The system has a front page. A new hire opens the architecture and sees the modules, how data moves between them, which services own which data, and where the external boundaries are — in minutes, not weeks of grepping.
- "Where does this go?" answers itself. Instead of asking a senior where a new feature belongs, the new hire sees the module map and the boundaries, and the right home is obvious from the picture.
- Drift is visible, not buried. Three different "user" shapes don't hide across forty files; they show up as an inconsistency in the model. The new hire stops reproducing the mess because they can see it's a mess.
- Change has a previewable blast radius. Before touching anything, you can see what a module connects to. The new hire's terror — "what will this break?" — gets a real answer from the dependency graph instead of a prayer.
This is the same idea behind building software with AI you can see: the architecture is the source of truth, the AI fills it in, and humans review the picture instead of an endless wall of diffs. For onboarding specifically, the payoff is that the picture is the curriculum. There's nothing to write up separately, because the thing the new engineer needs to learn is the thing they're already looking at and editing.
Visual ≠ a diagram you maintain by hand
Worth being blunt: hand-drawn architecture diagrams are worse than nothing for onboarding, because they're confidently out of date. A diagram that disagrees with the running system actively mis-trains the new hire. Visual architecture earns its keep only when it's authoritative — generated from, or used to generate, the real system, so it can't silently lie. The gap between "a picture of the architecture" and "the architecture is the picture" is the entire gap between a slide deck and a system.
The day-one experience: two new hires, two worlds
Make it concrete. Same company, same Tuesday, two new senior engineers, two very different first weeks.
Engineer A joins a prompt-built codebase. The app was vibe-coded fast with Cursor and an agentic tool over six months by two founders. On day one, A clones a repo of 80k lines with a README that covers setup and nothing else. The architecture lives in the founders' heads and a Slack channel of old AI conversations. A's first PR — a small change to how invoices are emailed — touches a service that, unknown to A, is also the path for password resets, because the AI once consolidated them in a prompt nobody remembers. The PR breaks auth in staging. Two seniors spend an afternoon explaining the implicit coupling. A spends week one feeling stupid and week two afraid to touch anything. Ramp: months.
Engineer B joins an architecture-first codebase. Same product, but the system was modeled visually — modules, data flows, contracts — and the AI generated structured objects inside that model, validated before deploy. On day one, B opens the architecture, sees the Billing module, sees that Email is a shared service with explicit consumers (including Auth), and sees the contract for the invoice flow. The same invoice change is now obviously scoped: B can see exactly what Email connects to before writing a line. B's first PR is correct because the boundary was visible. Ramp: weeks, maybe less.
The difference between A and B isn't talent, seniority, or effort. It's whether the system's architecture was a thing they could see on day one, or a thing they had to suffer into existence in their own head over a quarter. You hired the same engineer. You handed them two completely different jobs.
That's the entire thesis in one story. Onboarding speed is downstream of architectural legibility, and architectural legibility is a choice you make when you decide how AI is allowed to build.
How AI changed onboarding — for worse, then for better
There's a real research signal under the "AI codebases are harder to onboard into" claim, and it's worth citing precisely rather than on vibes. Research from McKinsey on generative AI and developer productivity found that while AI tools meaningfully speed up code generation, the gains shrink — and can reverse — on complex, unfamiliar tasks where developers must reason about an existing system's structure, and that the output still requires careful human review to stay maintainable. Put plainly: AI lets a team produce far more code, but not automatically more coherent code. And incoherent code is exactly the kind that's hardest to onboard into — high surface area, low coherence, lots of near-duplicate patterns a new hire has to disambiguate.
Layer on the workforce reality. According to Google's DORA State of DevOps research, the vast majority of developers have now adopted AI tools in their daily workflow, yet trust in the output of those tools remains notably mixed — and AI's benefits show up only when teams have the surrounding practices to absorb it. So your new hires arrive already leaning on AI, generating code against a system they don't understand yet, at machine speed. Without a legible architecture, that's a recipe for confident, fast, wrong contributions in week one. The exact opposite of fast onboarding.
But the same shift cuts the other way once the architecture is explicit. AI is a phenomenal onboarding accelerator when it can read a real model of your system:
- It can answer "what connects to
Billing?" from the actual dependency graph instead of hallucinating. - It can generate plain-language summaries of each module from the architecture, not from a guess.
- It can scaffold the new hire's first feature inside the existing structure, reusing components that already exist instead of spawning a fifth way to do the same thing.
The pivot is whether the AI is reasoning over an explicit architecture or reverse-engineering raw files. That's the same fork we cover for engineering leaders in AI development for CTOs: give the model structure and it's a multiplier; let it free-prompt and it's a debt machine.
The token math nobody mentions in the onboarding conversation
Here's the second-order effect that surprises people. The same missing artifact that slows your human onboarding — an explicit architecture — is what makes your AI usage expensive. Every time a code assistant has to re-derive your system's structure inside a prompt, you pay for it in tokens and in inconsistency.
When the architecture is modeled and the AI generates inside it, the model doesn't re-explain your whole system on every request. It operates against the structure that's already there. That's where GitMir's claim of up to ~15x fewer LLM tokens than ad-hoc prompting comes from: you're not re-paying to teach the model your architecture on every call. And the onboarding angle is that this is the same fix. A legible architecture onboards humans faster and re-onboards the AI cheaper, because both stop reconstructing the system from nothing. If you want the dollars, see how the token economics work — and try the GitMir IDE free.
A 30-day onboarding playbook built on visual architecture
Concrete beats inspirational. Here's a structure that compresses ramp time, assuming you have (or are moving toward) an explicit architecture.
Week 1 — See the system, change nothing structural
- Tour the architecture, not the code. Day one is navigating the visual model: modules, data flows, external boundaries, the few core contracts. The goal is the map, not the territory.
- Ship one trivial, well-scoped change inside a single module with a visible boundary — a copy tweak, a validation rule. The point is the first green deploy and the muscle memory of the workflow, not impact.
- Read three contracts end to end. Pick the three most-touched APIs or data flows and have the new hire trace them through the model. Contracts are the grammar of the system.
Week 2 — Build inside the boundaries
- First real feature, scoped by the model. Assign work whose blast radius the new hire can see before starting. Let them point at exactly which modules it touches and confirm with a senior in five minutes, not fifty.
- Use the AI as a guided tool, not a free agent. Have them generate inside the architecture and watch the validation gate catch a boundary violation. Feeling the system refuse a bad change is worth ten lectures about conventions.
Weeks 3–4 — Cross boundaries, then teach
- A feature that spans two modules. Now they learn how the system composes — and they'll appreciate why the boundaries exist, because they just had to respect one.
- Have them write one Architecture Decision Record. Documenting a single "why" forces them to internalize the system's reasoning, and it surfaces whatever they still don't understand.
- The graduation test: they answer the next new hire's question. When a new engineer can correctly explain "where does this go and what will it touch" to someone greener than them, they're onboarded. Not before.
The whole playbook is organized around one principle: bound the blast radius of everything a new hire does until their mental model is trustworthy, and use a visible architecture to make those bounds obvious instead of tribal.
Where the tools sit (and where they don't help onboarding)
Be fair about the landscape, because every tool here is good at something — just not always at this.
| Tool | Great at | What it does for onboarding | Gap for onboarding |
|---|---|---|---|
| Cursor / Copilot | In-editor generation, autocomplete, fast edits | Helps a ramped engineer move faster | No system-level model; new hire still has to build the map in their head |
| v0 / Lovable | UI and front-end scaffolding from prompts | Fast first screens | Generates artifacts, not a navigable architecture to learn |
| Replit Agent | Agentic build/run in one environment | Quick end-to-end prototypes | The structure lives in generated files, not an explicit model |
| Bubble | No-code visual app building | Visual, so newcomers see something | Locked into a proprietary runtime; not your real codebase's architecture |
| GitMir | Visual architecture + AI generating validated objects inside it | The architecture is the onboarding surface; AI reads the model | Requires modeling up front (worth it for anything a team lives in for months) |
The honest read: editor-level assistants like Cursor and Copilot make a fluent engineer faster but do nothing to shorten the comprehension phase that dominates onboarding — they have no durable picture of your system to hand over. Prompt-to-app tools like v0, Lovable, and Replit Agent get you to running software fast but leave the architecture implicit, which is the exact thing a new hire needs explicit. Bubble is genuinely visual, which helps newcomers, but it's a closed platform, not your production stack.
GitMir's bet is the one this whole article argues for: make the architecture a visual, authoritative object, let AI generate structured, editable objects inside it with validation before deploy and reusable components instead of regenerated duplicates — so the system a new engineer needs to learn is the same system they can see and edit. None of these is "the onboarding tool." But only the architecture-first approach attacks the part of onboarding that actually costs you money. See the mechanics on the product page, or the head-to-head on the comparison page.
The leadership reframe: onboarding speed is a system property
Stop treating onboarding as an HR-adjacent process you improve with better docs and a checklist. It's an emergent property of your architecture's legibility. A legible system onboards fast no matter who you hire; an illegible one onboards slowly no matter how good your buddy program is. You don't fix slow onboarding with a better wiki. You fix it by making the architecture something a human — and a model — can see.
This reframe also future-proofs you. The trend is unambiguous: more code, generated faster, by humans leaning harder on AI. The teams that win the next few years won't be the ones who generate the most. They'll be the ones whose systems stay understandable as they grow — where a new engineer or a new model can be productive in week one because the architecture was never allowed to become a thing only a few brains hold. Keeping the architecture legible is the same discipline that keeps your documentation true automatically: make the map and the territory the same object, and the map can't go stale.
Your onboarding speed in two years is being decided right now, in how you let AI build today. Every prompt that adds code without adding to a legible architecture is a prompt that lengthens the ramp of every engineer you haven't hired yet.
Next step: put a number on it
If onboarding pain is real on your team, don't argue it with anecdotes — quantify it. Estimate your current ramp time, multiply by your loaded engineer cost, and add the senior-hours you spend re-explaining the system, and you'll have a number that justifies the work overnight. The ROI calculator does exactly this math, including the token side of re-onboarding the AI.
Then see what architecture-first development actually looks like: how a visual model becomes the surface a new engineer navigates, how AI generates validated objects inside it, and why reusable components beat regenerated duplicates for both onboarding and cost. Start with the product overview, compare it against your current stack on the comparison page, and if you're an engineering leader weighing the broader bet, AI development for CTOs frames the decision end to end. The goal isn't faster onboarding as a perk. It's a system that stays understandable while it grows — which is the only version of "fast" that lasts.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
How does visual architecture actually speed up engineer onboarding?
It hands the new hire an explicit map instead of forcing them to reverse-engineer one. Most ramp time is spent building a mental model of how modules, data flows, and boundaries fit together. When that model is visual and authoritative, the new engineer absorbs the system in days rather than excavating it through weeks of questions, grepping, and broken first PRs.
How long should onboarding a new software engineer take?
Realistically, two to six months to full productivity, depending on system complexity and how legible your architecture is. The variance is almost entirely comprehension, not coding skill. A clean, visible architecture can compress meaningful productivity to a few weeks; an undocumented, AI-bloated codebase can stretch a senior engineer's ramp past a full quarter and tax your other seniors throughout.
Does using AI coding tools make onboarding faster or slower?
Both, depending on whether the AI works inside an explicit architecture. Free-prompting tools like Cursor and Copilot generate high-volume, often duplicated code that inflates the surface area a new hire must learn, slowing onboarding. But when AI reads a real architectural model, it accelerates onboarding by answering dependency questions accurately and scaffolding first features inside existing structure instead of guessing.
What's the biggest hidden cost of slow onboarding?
Senior engineer time, which is double-counted and rarely tracked. Every question a new hire asks is both their own lost output and an expensive senior's interrupted deep work, and context-switching makes the senior's cost far worse than the clock time suggests. Across a year of hires on an illegible codebase, this comprehension overhead easily reaches six figures and silently caps team velocity.
Can good documentation replace visual architecture for onboarding?
No — static docs decay faster than the system changes, so they confidently mislead new hires the moment they drift. Onboarding speed comes from an architecture that's authoritative because the code is built and validated against it, not from prose maintained by hand. Documentation helps capture the why behind decisions, but it can't substitute for a legible, living model of the system itself.
How do I onboard engineers faster onto an existing AI-generated codebase?
Start by making the implicit architecture explicit — model the modules, data flows, and contracts that already exist so new hires get a map instead of raw files. Then bound every early task to a visible blast radius, use AI as a guided tool inside that structure rather than a free agent, and require one Architecture Decision Record to force genuine system understanding.

Related articles

How to Document Software Architecture (Almost) Automatically
Architecture docs go stale the moment they're written. The fix isn't more discipline — it's making the architecture itself the living source of truth. Here's how.

AI Development for CTOs: Speed Without Losing Control
AI lets your team ship faster — and accumulate invisible risk faster. Here's how CTOs capture the speed while keeping architecture, quality and cost under control.

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.