
AI Coding Without Hallucinations: Keep AI From Breaking Your Architecture
AI doesn't 'hallucinate' randomly — it invents code when it can't see the system. Give it structure and validation, and the hallucinations stop being your problem.
AI doesn't hallucinate because the model is dumb. It hallucinates because you gave it no constraints. When an LLM generates code, it predicts the most plausible next tokens given the context window, and "plausible" is not the same thing as "correct," "consistent with your existing system," or "wired to the function that actually exists in your repo." Strip away the constraints and you get confident, well-formatted code that calls a method you never wrote, invents an API shape that doesn't match your backend, or quietly re-implements a service you already have three copies of.
So the honest answer to "how do I stop AI from breaking my architecture?" is this: you can't make the model stop guessing, but you can shrink the space it's allowed to guess in. Hallucinations are an architecture problem wearing a model problem's clothes. The teams shipping reliable AI-generated code aren't running a smarter model than you. They're feeding the model a tighter, more explicit picture of the system it's editing, and they validate the output against that system before it ever touches production.
This article is the playbook for doing exactly that. We'll cover why hallucinations happen mechanically, the specific ways they corrode an architecture, and the concrete controls — from prompt hygiene to validation gates to architecture-first tooling like GitMir — that keep AI generating code inside your system instead of around it.
What an AI Hallucination Actually Is in Code
A hallucination in coding isn't a typo or a logic bug in the usual sense. It's the model producing output that's internally coherent but externally false: code that looks right and references things that don't exist or don't behave the way the model assumed.
The common forms:
- Phantom APIs — calling
db.findUserByEmailOrThrow()when your ORM only hasfindUnique. The name is plausible, so the model invents it. - Drifted contracts — the AI assumes your
/api/ordersendpoint returns{ items: [...] }when it actually returns{ data: { orders: [...] } }. Now the frontend silently renders nothing. - Package hallucinations — importing a real-sounding npm package that doesn't exist (or worse, one an attacker has squatted because models hallucinate the same fake name repeatedly).
- Re-invention — writing a brand-new
formatCurrencyhelper when you already have one, because the model never saw your utils folder. - Confident wrong assumptions — "since this is a Next.js app, I'll use server actions" — in a repo that deliberately doesn't.
A hallucination isn't the model lying. It's the model filling a gap in its context with the most statistically average answer — and your codebase is not average.
Every one of these traces back to the same thing: the model didn't know something it needed to know, and nothing stopped it before that gap became committed code. If you want a deeper taxonomy of the failure modes and how to catch them, we wrote a dedicated guide on how to validate AI-generated code.
Why Hallucinations Happen: It's a Context Problem, Not an IQ Problem
Models hallucinate for three structural reasons. Understand them and you know exactly which levers move the needle.
1. The context window is a keyhole
Your codebase might be 200,000 lines. The model sees, at best, a few thousand lines of whatever your tool decided to retrieve. Everything outside that keyhole is invisible, and the model fills invisible space with assumptions. Tools like Cursor and GitHub Copilot do retrieval to widen the keyhole, but retrieval is heuristic. It grabs files that look relevant, not necessarily the ones that define the contract you're about to break.
2. Generation is probabilistic by design
LLMs sample from a probability distribution. Lower the temperature and you get more deterministic output, but you never get zero improvisation, because the model is completing a pattern, not looking up a fact. When the right answer is rare or project-specific, the average answer wins.
3. There's no ground-truth check in the loop
A human engineer who isn't sure whether a function exists will grep for it. A raw LLM doesn't grep. It commits to an answer. Without a tool feeding back "that symbol doesn't resolve," the model has no signal that it just made something up. This is the single biggest difference between a chatbot pasting code and a real AI coding agent that can run, type-check, and read its own errors.
This isn't a fringe worry. Research from McKinsey on generative AI in software engineering found that while AI tools can meaningfully speed up code generation, the gains erode when the output isn't grounded in the existing system — developers spend the saved time re-reviewing and reworking code that doesn't fit, especially on complex, unfamiliar codebases. That's architectural drift showing up in the workflow. The model, unable to see the helper that already exists, generates a plausible new one. Reliability isn't only about the obvious phantom-API crash. It's about this slow accumulation of redundant, contract-violating code that no single review ever flags.
So you reduce hallucinations by three moves: widen and sharpen the context, constrain the output space, and close the loop with validation. The rest of this article is those three moves, made concrete.
How Hallucinations Quietly Break Your Architecture
A single hallucinated line is rarely catastrophic. The damage is cumulative, and it shows up in patterns that look like normal entropy until you trace them back.
Here's the mechanism. AI codegen is cheap, so you generate a lot. Each generation makes a local assumption to fill a context gap, and those local assumptions don't agree with each other. After a few hundred generations you have:
- Three different ways of doing the same thing — because each session re-invented the data-fetching pattern.
- Contract drift between layers — the API and the client disagree on shapes because they were generated in separate sessions with separate assumptions.
- Dead and duplicated code — helpers, types, and components that were re-created instead of reused.
- Invisible coupling — code that works today because of an assumption that's true today, and breaks the moment that assumption changes.
This is how a codebase becomes unmaintainable without a single dramatic failure: death by a thousand plausible guesses. We catalogued the warning signs in the signs your AI codebase is becoming unmaintainable; architectural hallucination is the root cause behind most of them.
The scariest hallucinations aren't the ones that crash. They're the ones that work — until the assumption they're built on quietly stops being true.
The Core Principle: Constrain the Output Space
Every reliability technique below is a variation on one idea: the smaller and more explicit the space of valid outputs, the less room the model has to hallucinate.
Think of it as a spectrum:
| Approach | What the model sees | Hallucination risk |
|---|---|---|
| Chat with copy-paste | Just your prompt | Highest — no repo awareness |
| Autocomplete (Copilot) | Local file + a few neighbors | High — local context only |
| Agentic IDE (Cursor, Replit Agent) | Retrieved files + tool feedback | Medium — depends on retrieval quality |
| Prompt-to-app (Lovable, v0, Bubble) | A template/framework scaffold | Medium — bounded but opaque |
| Architecture-first (GitMir) | An explicit model of the system | Lowest — generation happens inside defined structure |
The tools higher in that table aren't worse. They're solving a different problem. v0 and Lovable are excellent at going from nothing to a working UI fast. Cursor and Copilot are excellent at accelerating an engineer who already holds the architecture in their head. The risk scales with how much of the system the model has to infer versus how much it's told.
GitMir sits at the bottom of that table on purpose. Instead of letting AI free-write into a repo and hoping retrieval surfaces the right context, you build the architecture visually first — modules, data flows, APIs, business logic — and the AI generates structured, editable objects inside that architecture. The model isn't guessing what your Order entity looks like or which endpoint to call. The architecture is the context, and it's explicit. That's also why it burns roughly 15x fewer tokens than ad-hoc prompting: you're not re-shipping the entire codebase into the context window every session to remind the model what already exists.
Eight Controls That Keep AI Inside Your Architecture
Here's the practical layer — the controls that actually move hallucination rates, roughly in order of leverage.
1. Make the architecture explicit and machine-readable
The model can't violate a contract it can clearly see. Give it explicit schemas, types, interface definitions, and data-flow boundaries, not prose descriptions buried in a README. A typed API contract (OpenAPI, GraphQL schema, tRPC, Protobuf) eliminates an entire class of contract-drift hallucinations because the shape is no longer something the model has to guess.
In a free-form repo, you do this with strict types and shared schema packages. In an architecture-first system like GitMir, the architecture is the contract — the AI generates against modeled modules and data flows, so the "schema" isn't optional documentation. It's the thing generation is anchored to.
2. Force the model to ground itself before generating
Don't ask for code in the first turn. Make the model:
- List the existing functions, types, and files relevant to the task.
- Quote the actual signatures it intends to call.
- State its assumptions explicitly.
- Then generate.
This "show your work" step turns silent assumptions into visible ones you can catch. Agentic tools that can grep and read files do a version of this automatically, which is exactly why an agent that runs tools beats a chat window that just emits text.
3. Constrain with reusable components, not freehand code
Every time the AI writes a component from scratch, it re-rolls the dice on your conventions. Compose from existing, validated building blocks instead and it can't drift. Maintain a real library of components, hooks, and utilities, and make the AI reach for them first. That's the structural reason reusable components reduce hallucinations: a reused component is a guess the model never has to make.
4. Validate before deploy — automatically, not by vibe
This is the loop-closer. Output that isn't checked against reality is just a confident guess. Your minimum validation gate:
- Type checking — catches phantom APIs and shape mismatches instantly.
- Compilation/build — catches imports of packages and modules that don't exist.
- Linting with custom rules — enforces "use the shared helper, don't re-implement."
- Contract tests — assert the API returns the shape the client expects.
- A smoke test of the happy path — does the thing actually run?
No AI-generated change should reach production without passing these. GitMir bakes this in as validation before deploy — generation is checked against the modeled architecture, so a hallucinated object fails at design time, not in a 2 a.m. incident.
5. Keep generations small and reviewable
A 600-line AI diff hides hallucinations in volume. A 40-line diff doesn't. Smaller units mean each one is fully reviewable, the model has less room to invent connective tissue, and a bad generation is cheap to throw away. Big-bang generation is where contract drift breeds.
6. Pin and verify dependencies
Package hallucinations are a real supply-chain risk. "Slopsquatting" exists because models invent the same plausible-but-fake package names repeatedly. Pin versions, use a lockfile, and fail CI on any import that isn't already an explicit dependency. Never let an AI add a dependency you didn't approve.
7. Lower the temperature for code, raise it for ideas
Use a near-deterministic setting when generating code that has to fit an existing system, and save higher creativity for greenfield brainstorming. Most coding tools default sensibly here, but if you're calling the API directly, this is a free reliability win.
8. Treat the human as the architect, the AI as the implementer
The most reliable workflow keeps the human owning the structure and the AI owning the fill. The moment you let AI make architectural decisions — where should this live, what should the contract be — you've handed it the one job it's worst at, because those decisions require global knowledge the keyhole can't provide.
A Concrete Scenario: Adding a "Refund" Feature
Let me make this real. Say you're adding refunds to a payments app. Two paths.
The unconstrained path (chat or autocomplete):
- You prompt: "add a refund endpoint and a refund button."
- The model invents
paymentProvider.issueRefund(orderId)— but your provider wrapper actually exposesrefundCharge(chargeId, amountCents). - It assumes
Orderhas achargeIdfield. It doesn't; charges live on a separateTransaction. - The endpoint returns
{ success: true }; the button expects{ refund: { id, status } }. - It compiles in the file you're looking at, fails at runtime, and you spend two hours debugging an architecture the AI never actually understood.
The constrained path (architecture-first):
- The
Order,Transaction, andPaymentProvidermodules already exist as modeled objects with explicit fields and methods. - You define the refund flow against those, so the AI can only generate against the real
refundChargesignature and the realTransaction.chargeId. - The endpoint's response shape is the modeled contract; the button consumes that same contract. They can't disagree.
- Validation runs before deploy: a mismatch would fail at design time.
- The refund logic reuses the existing transaction-lookup component instead of re-inventing it.
Same model, same intelligence. The difference is entirely in how much the system was told versus left to guess. That's the whole game. You can see how this compares across tools on the comparison page.
Common Mistakes Teams Make
The failure patterns are remarkably consistent:
- Trusting fluency. Well-formatted, confident code reads as correct. Fluency is not accuracy — the most dangerous hallucinations are the best-written ones.
- Reviewing for style, not contracts. Reviewers catch a bad variable name and miss that the function being called doesn't exist. Review against the architecture, not the prose.
- No validation gate. "It worked when I tried it" is not a gate. If nothing automatically rejects hallucinated output, hallucinations ship.
- Letting the AI choose where things live. Architectural placement is a global decision; the model only has local context. Own this yourself.
- Generating huge diffs. Volume hides drift. Keep units small.
- Re-prompting instead of constraining. When the AI hallucinates, the instinct is to write a longer prompt. The fix is usually a tighter system, not a wordier request.
If your only defense against hallucination is "I'll catch it in review," you've already lost — because the whole point of a good hallucination is that it survives a casual review.
The Reliability Stack, Layered
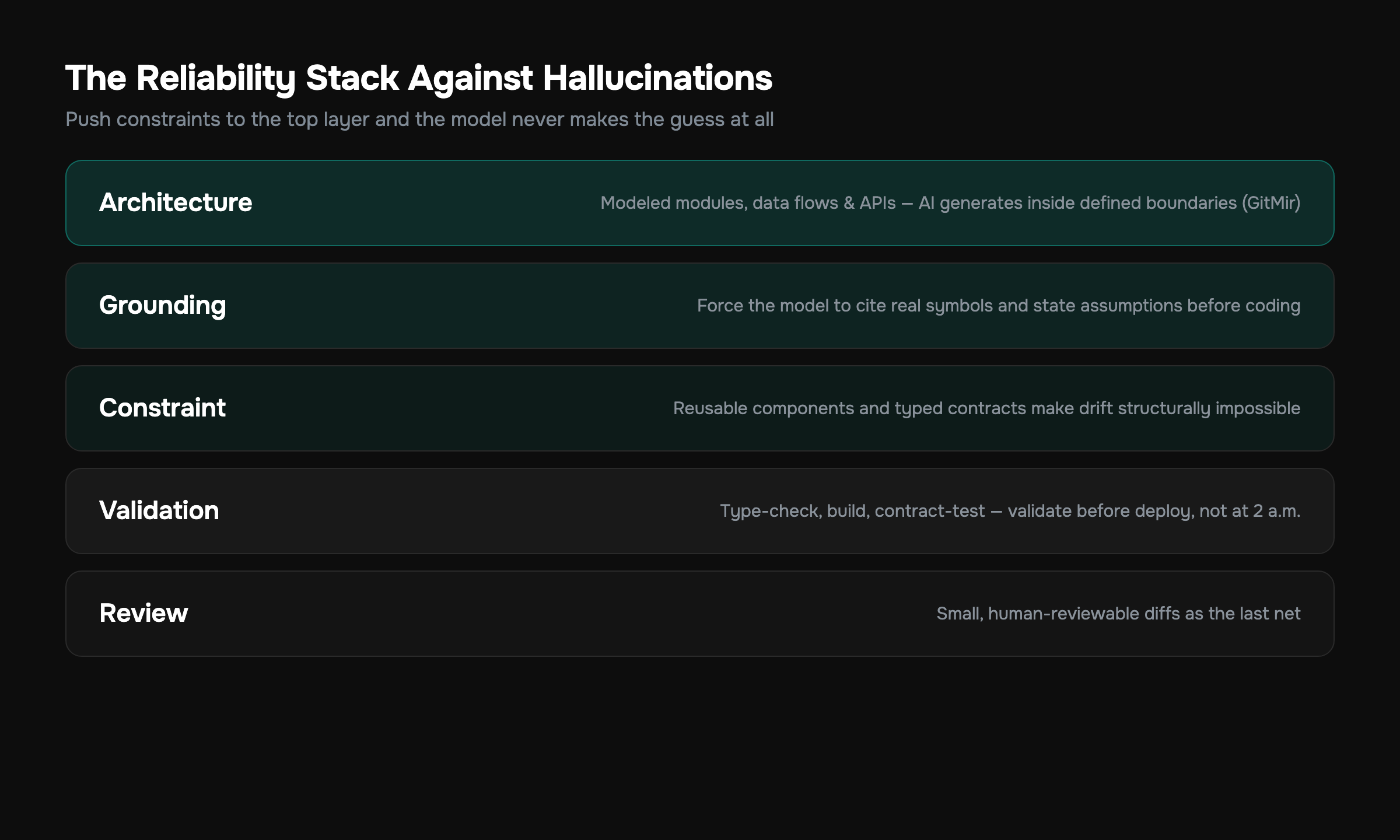
Put together, your defenses form a stack, and each layer catches what the one above missed:
- Architecture layer — explicit, modeled structure so the model generates inside defined boundaries (fewest hallucinations enter at all).
- Grounding layer — force the model to reference real symbols and state assumptions before coding.
- Constraint layer — reusable components and typed contracts so drift is structurally impossible.
- Validation layer — type-check, build, contract-test, and validate before deploy.
- Review layer — small human-reviewable diffs as the last net.
Most teams have only layers 4 and 5, and they're drowning. The leverage is at the top. The cheapest hallucination to fix is the one the architecture never let the model make. That's the bet GitMir makes: push the constraints up to layer 1 so the lower layers have far less to catch, and you spend ~15x fewer tokens doing it because the model isn't re-deriving your system every session.
What This Buys You
Concretely, teams that move hallucination control up the stack get:
- Fewer 2 a.m. incidents from code that compiled but assumed wrong.
- A codebase that stays coherent as AI generation volume scales up.
- Faster onboarding — the architecture is explicit, so humans and AI read the same map.
- Lower cost per change — fewer tokens, fewer debugging hours, fewer re-generations.
The trade-off is real and worth naming. Architecture-first requires you to model the system before you generate, which feels slower on day one than firing prompts at a blank repo. The payoff is that day 30 doesn't collapse under the weight of accumulated guesses. For a greenfield prototype you'll throw away, unconstrained prompt-to-app tools win. For a system you intend to maintain and scale, constraint wins every time.
Next Step
Hallucinations aren't a model flaw you wait out. They're a constraint problem you design around. The move is to stop asking AI to understand your architecture and start making it generate inside one.
If you want to see what that looks like in practice, walk through the product to see architecture-first generation and validation-before-deploy in action. If you're trying to justify the switch, run the numbers on the ROI page — the token savings and the debugging hours you stop losing to hallucinated code are usually the whole argument. And if you're weighing it against your current setup, the tool comparison lays out where Cursor, Copilot, Lovable, v0, Replit Agent, and Bubble fit versus an architecture-first approach. Then start free in the GitMir IDE when you're ready to put it on a real project.
See it on your own numbers
GitMir gives you visual architecture, reusable components and up to 15× fewer LLM tokens. Try the visual IDE for Claude Code free, or estimate your savings first.
Start free in GitMir IDE → Calculate your ROI →Frequently asked questions
Can AI coding tools ever fully stop hallucinating?
No tool can make an LLM stop guessing, because generation is probabilistic by design. What you can do is shrink the space it's allowed to guess in — explicit architecture, typed contracts, reusable components, and automated validation before deploy. The goal isn't a model that never improvises; it's a system that catches or prevents improvisation before it ships.
Why does AI invent functions and APIs that don't exist in my codebase?
Because the model only sees a small slice of your codebase through the context window, and it fills the invisible parts with the most statistically plausible answer. A function name like findUserByEmailOrThrow sounds right, so the model commits to it even though your code only has findUnique. Giving the model explicit, machine-readable signatures and forcing it to reference real symbols before generating eliminates most of these phantom calls.
What's the single most effective way to reduce AI hallucinations in code?
Make your architecture explicit and validate generated output against it automatically. Typed contracts and modeled data flows remove the gaps the model would otherwise fill with guesses, and a validation gate (type-check, build, contract tests) rejects anything that slipped through before it reaches production. Constraining the output space beats writing longer prompts almost every time.
How is GitMir different from Cursor or Copilot for preventing hallucinations?
Cursor and Copilot accelerate an engineer who already holds the architecture in their head, relying on retrieval to surface context — which is heuristic and can miss the contract you're about to break. GitMir makes the architecture explicit first: you model modules, data flows, and APIs visually, and AI generates structured objects inside that architecture, validated before deploy. The model isn't inferring your system; it's generating against a defined one, which also uses roughly 15x fewer tokens.
Do hallucinations matter if the code compiles and runs?
Yes, often more — the most dangerous hallucinations are the ones that work today. Code built on a wrong-but-currently-true assumption (a field that happens to exist, an endpoint that happens to return the right shape) passes review and runs fine until the assumption changes, then breaks in a way that's hard to trace. Contract tests and architectural validation catch these where a "it ran when I tried it" check never will.
Will an architecture-first workflow slow my team down?
On day one, modeling the system before generating feels slower than firing prompts at a blank repo. By day 30 it's faster, because you're not paying down a debt of accumulated, conflicting guesses or debugging hallucinations in production. For throwaway prototypes, unconstrained prompt-to-app tools are fine; for anything you intend to maintain and scale, the upfront structure pays for itself quickly.

Related articles

How to Validate AI-Generated Code Before It Ships
AI writes confident code that's sometimes wrong. A repeatable validation process catches the failures before production. Here's a practical checklist plus the system-level fix.

7 Signs Your AI Codebase Is Becoming Unmaintainable
AI-built codebases can rot quietly until a small change takes a week. Here are seven early warning signs — and what to do before it's a rewrite.

How to Migrate Legacy Software with AI (Without a Blind Rewrite)
Most legacy migrations fail because nobody fully understands the system being moved. The fix isn't translating code — it's capturing the product as a 28-dimensional model first, so AI can re-platform and refactor it with real context.